[Microsoft AI School 6기] 1/16(21일차) 정리 - 통계 기반 데이터 활용, MLD, 머신러닝, 분류 모델 실습:데이터 전처리
통계 기반 데이터 활용
개요
데이터와 통계
통계와 관련된 책 소개
제목: Factfulness

- 저자는 인간은 세상을 이분법적으로 분류하려는 간극 본능을 가지고 있다고 함
- 통계에 의해 세상을 바라보아야 하며 우리는 편견을 가지기 쉬움
- Gapminder 재단 운영중
Gapminder Website
https://www.gapminder.org/tools/#$chart-type=bubbles&url=v2
Gapminder Tools
Animated global statistics that everyone can understand
www.gapminder.org
통계
- 통계 기본 개념
- 기술 통계
- 확률과 분포
- 추정과 가설 검정
- 상관분석: ex) HeatMap
머신러닝
- 데이터 기반으로 학습
- 주어진 데이터 속에서 규칙을 학습
- 학습한 규칙을 기반으로 새로운 데이터에 대한 예측
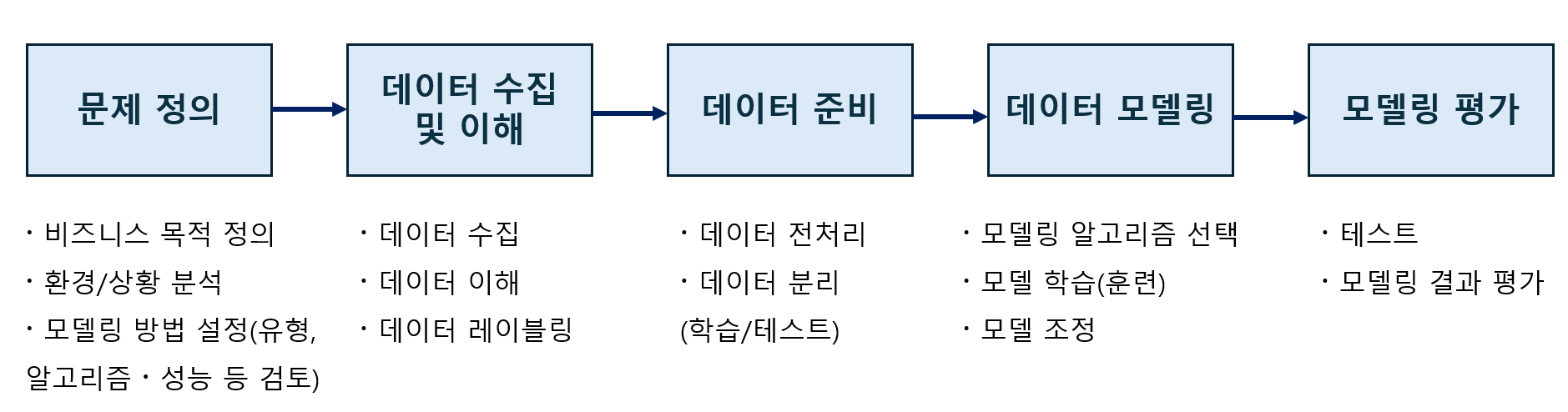
머신러닝 절차
문제 정의 -> 데이터 수집 및 이해 -> 데이터 준비 -> 데이터 모델링 -> 모델링 평가
Azure Machine Learning
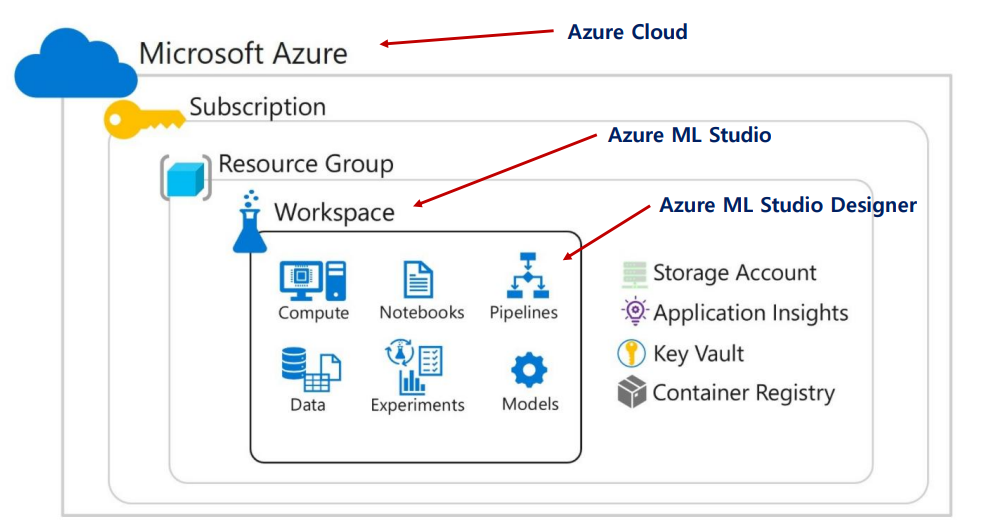
Azure의 구조는 위와 같다. 총 3단계로 구성되며 상위 단위를 삭제할 경우 하위 단위가 같이 삭제되기 때문에 유의해야 한다.
RESTful API
데이터 교환을 위해 설계된 HTTP 기반 API

- REST(Representational State Transfer) 아키텍처 스타일을 따르는 API
- REST는 분산 시스템(특히 웹)을 설계하기 위한 원칙과 제약 조건을 정의하며, RESTful API는 이를 구현한 웹 서비스
- HTTP 프로토콜을 기반으로 클라이언트와 서버 간에 데이터를 교환하며, URL을 통해 자원을 식별하고 HTTP 메서드를 사용해 자원에 대한 작업을 수행
통계 기초
통계의 기본 개념
통계학은 데이터를 수집, 분석, 해석 및 표현하는 과학으로서, 이를 통해 불확실성을 다루고 데이터 기반 의사 결정을 지원하는 학문
목적
- 데이터로부터 유의미한 정보 도출
- 현상 및 패턴 이해
- 연관성 파악
- 예측 및 추론
- 불확실성의 해소
- 의사 결정 지원
중요성
- 데이터를 수치화하여 신뢰성을 부여
- 의사 결정을 위한 근거 자료를 제시
- 현상을 분석하여 실증 자료를 제시
기술통계와 추론 통계

- 기술 통계는 통계값을 구하는 게 목적
- 추론 통계는 모집단의 특성을 파악하기 위함
즉, 모집단의 특성을 알 수 없을 때 추론하는 것이 추론 통계
표본의 추출
확률적 표본 추출 (Probability Sampling Method)
- 동일한 확률 하에서 표본을 추출하는 방법
- 무작위 표본 추출: 난수표 등을 따라 모집단에서 표본을 기계적으로 추출하는 방법
- 체계적 표본 추출: 모집단에서 특정한 규칙으로 표본을 추출하는 방법
- 층화 표본 추출: 모집단을 특정 특성에 따라 여러 하위 집단으로 구분한 후, 집단의 규모에 비례하도록 추출하는 방법
비확률적 표본 추출 (Non-probability Sampling Method)
- 조사자가 자의로 표본을 추출하거나 조사 대상이 자발적으로 표본에 참여하는 방법
기술 통계
중심경향성(Central Tendency)
표본 내의 원소들의 중심을 나타내는 지표
평균, 중앙값, 최빈값 등 아양한 방식으로 표현됨
평균(Mean): 모든 값을 더한 후 데이터의 개수로 나눈 값
장점: 데이터를 통합하여 하나의 대표값으로 표현
단점: 이상치(outliers)에 민감하여 극단적인 값에 영향을 받음
-> 연속적이고 정규 분포를 따르는 데이터에서 대표값을 구할 때 유용
중앙값(Median): 표본 내의 원소들을 크기 순서대로 나열했을 때 중앙에 위치한 값
장점: 이상치의 영향을 덜 받음
단점: 표본의 크기가 클 경우 정렬에 많은 시간 소요
-> 비대칭적이거나 이상치가 있을 때 사용
최빈값(Mode): 표본에서 가장 자주 나타나는 값
장점: 표본의 원소들의 빈포 분포를 잘 나타냄
단점: 표본 내의 최빈값이 존재하지 않을 수 있으며, 복수 개의 최빈값이 있을 수도 있음
-> 범주형 데이터에서 빈도가 가장 높은 값을 찾을 때 유용
가중 평균(Weighted Mean): 표본의 원소들의 값에 가중치를 부여하여 계산한 평균
-> 모든 원소들의 값이 동일한 중요도를 가지지 않을 때 사용
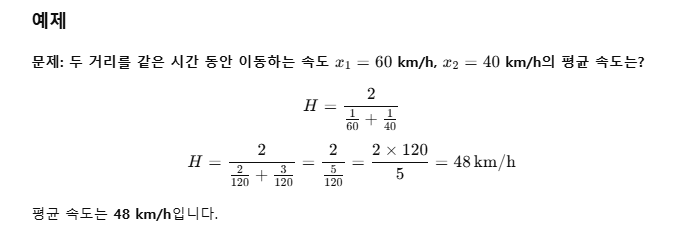
조화 평균(Harmonic Mean): 원소들의 값들의 역수의 평균을 다시 역수로 변환하여 계산
-> 주로 비율이나 속도 데이터에서 사용

산포도 측정
산포도(Measure of Dispersion)
- 통계에서 산포도를 측정하는 방법들은 데이터의 변동성을 파악하는 데 중요한 역할을 함
범위(Range)
- 표본 집합에서 가장 큰 값과 가장 작은 값의 차이
- 단순해서 많이 사용, 극단값(outlier)에 민감
Range = max-min
분산(Variance)
- 데이터 값들이 평균에서 얼마나 떨어져 있는 지를 나타냄
- 계산 방법: 편차 제곱의 평균, 제곱의 평균 - 평균의 제곱
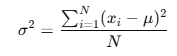
표준편차(Standard Deviation)
- 분산의 제곱근으로 데이터가 평균에서 얼마나 떨어져 있는 지에 대한 표준적인 거리를 나타냄
사분위수 범위(interquartile Range, IQR)
- 데이터의 중앙 50%가 포함된 범위로, Q3(3사분위수)와 Q1(1사분위수)의 차이
- 극단값의 영향을 덜 받음
왜도와 첨도
왜도(Skewness): 분포의 비대칭성을 측정하는 지표
첨도(Kurtosis): 분포의 뾰족함과 꼬리의 두꺼움을 측정하는 지표
왜도(Skewness) : 분포의 비대칭성을 측정하는 지표
양의 왜도 (Positive Skewness):
- 분포의 꼬리가 오른쪽(양의 방향)으로 길게 늘어져 있는 경우
- 평균이 중앙값보다 큼. (예: 급여, 주택 가격 등)
음의 왜도 (Negative Skewness):
- 분포의 꼬리가 왼쪽(음의 방향)으로 길게 늘어져 있는 경우
- 평균이 중앙값보다 작음. (예: 시험 점수 등)

첨도 (Kurtosis) : 분포의 뾰족함과 꼬리의 두꺼움을 측정하는 지표
양의 첨도 (Leptokurtic): (Kurtosis > 3)
- 정규 분포보다 뾰족하고 꼬리가 두꺼운 분포
- 극단적인 값(이상치)이 더 자주 발생함
음의 첨도 (Platykurtic): (Kurtosis < 3)
- 정규 분포보다 평평하고 꼬리가 얇은 분포
- 극단적인 값이 덜 발생

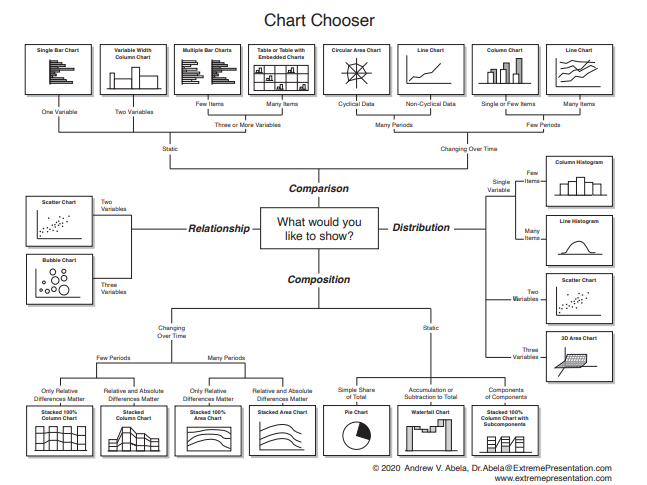
시각화의 필요성
시각화는 데이터의 패천을 파악하고 데이터가 의미하는 내용을 효과적으로 전달하며, 신속하고 정확한 의사 결정을 위한, 기술 통계 방법의 일종
- 데이터 이해
- 의사 소통
- 패턴 파악
- 의사 결정 지원
확률과 분포
확률
표본 공간 (Sample Space) : 실험을 통해 나타날 수 있는 모든 결과들의 집합
사건 (Event) : 표본공간에 있는 일부 원소들로 이루어진 부분 집합
확률 : 특정 사건이 일어날 가능성을 나타내는 척도(사건이 발생할 가능성을 수치로 표현)
- 0에서 1 사이의 값을 가지며, 0은 사건이 절대로 일어나지 않음을 의미하며, 1은 사건이 반드시 일어남을 의미함
확률 함수 (Probability Function) : 사건이 발생할 확률을 나타내는 함수
규칙
덧셈 법칙 : 두 사건 𝐴, 𝐵 에 대하여, 𝑃(𝐴 ∪ 𝐵) = 𝑃(𝐴) + 𝑃(𝐵) − 𝑃(𝐴 ∩ 𝐵)
곱셈 법칙 : 두 사건 𝐴, 𝐵 가 독립 사건일 때, 𝑃(𝐴 ∩ 𝐵) = 𝑃(𝐴) × 𝑃(𝐵 )
확률 변수(Random Variable)
: 특정 값이 나타날 가능성이 확률적으로 주어지는 변수
-> 표본 공간의 각 표본점에 실수 값을 대응시키는 함수 역할을 함.
-> 이산 확률변수와 연속 확률변수로 구분
표본점 (Sample point) :
모집단에서 무작위로 뽑은 하나의 표본
확률 표본 (Random sample) :
모든 표본점(sample point)들이 동일한 확률로 추출된다는 조건 하에서 추출된 표본
이산형 확률변수 (Discrete random variable)
- 0이 아닌 확률 값을 갖는 값이 셀 수 있는 경우의 확률 변수
-> 확률질량함수(Probability Mass Function) : 이산형 확률변수의 확률함수
이산형 확률변수에 의한 확률 분포 : 이항분포, 기하분포, 포아송분포 등
연속형 확률변수 (Continuous random variable)
- 연속적인 값을 가짐
- 가능한 값이 실수의 어느 특정 구간 전체에 해당하는 확률 변수
-> 확률밀도함수(Probability Density Function) : 연속형 확률변수의 확률함수
연속형 확률변수에 의한 확률 분포 : 정규분포, 균일분포, t-분포, 카이제곱분포 등
확률 분표
: 확률 변수가 가질 수 있는 값들과 그 값들이 발생할 확률을 나타내는 함수
이산 확률 분포 (Discret Probability Distribution)
- 확률 변수가 취할 수 있는 값이 유한하거나 셀 수 있는 경우
-> 확률질량함수(Probability Mass Function : PMF)로 표현
베르누이분포, 이항분포, 포아송분포
연속 확률 분포 (Continuous Probability Distribution
- 확률 변수가 취할 수 있는 값이 연속적인 경우.
-> 확률밀도함수(Probability Density Function : PDF)로 표현
정규 분포, 지수 분포, 카이제곱 분포
이산확률 분포-베르누이 분포(Bernoulli Distribution)
- 두 가지 결과(성공 또는 실패)가 있는 단일 시행의 확률분포
기대값 : 𝐸(𝑋) = p
이산확률 분포-이항 분포 (Binomial Distribution)
- 일정한 횟수의 독립적인 베르누이 시행에서 성공의 횟수를 나타내는 분포
확률변수 𝑋 : 𝑛 번의 독립적인 시행 중 성공 횟수
확률질량함수 (PMF) : 𝑘 번 발생할 확률
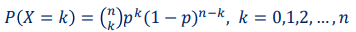
기대값 : 𝐸(𝑋) = 𝑛𝑝
분산 : 𝑉𝑎𝑟(𝑋) = 𝑛𝑝(1 − 𝑝)
이산확률 분포- 푸아송 분포 (Poisson Distribution)
- 단위 시간(또는 단위 공간)에서 특정 사건의 발생 빈도를 나타내는 분포
- 드물게 발생하는 사건의 빈도를 모델링할 경우 사용됨
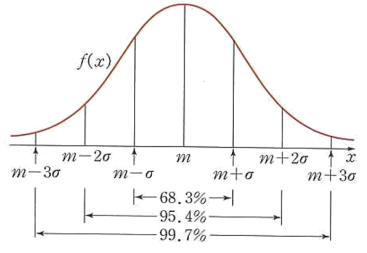
연속확률 분포- 정규 분포 (Normal Distribution)
- 종 모양의 대칭 분포로, 자연 현상에서 많이 나타나는 일반적인 분포
연속확률 분포- 지수 분포 (Exponential Distribution)
- 사건 간의 시간 간격에 대한 분포. 주로 포아송 과정에서 시간 간격을 모델링하는 데 사용
ex) 콜센터 대기 시간 : 다음 전화가 걸려올 때까지의 시간
연속확률 분포- 카이제곱 분포 (Chi-Square Distribution)
- 정규 분포를 따르는 독립적인 변수들의 제곱의 합의 분포
- 모집단의 분산을 추정할 때 주로 사용됨
추정과 가설검정
추론
- 표본을 활용하여 모집단의 특성을 추측
- 모집단 전체를 조사할 수 없을 경우 주로 사용
추론의 방법
- 모수의 추정(Estimation):
미지수인, 모지반의 모수에 대한 추측 또는 추측값을 정확도와 함께 제
- 모수에 대한 가설 검정(hypothesis Testing):
모집단의 모수에 대한 여러 가설들이 적합한지 여부를 표본으로 부터 판단
- 점추정 (Point Estimation):
모집단의 모수를 단일 값(점)으로 추정하는 방법
- 대푯값 : 일반적으로 표본평균, 표본분산 등이 사용됨
- 예시 : 표본평균이 50이라면 모집단 평균도 50으로 추정
- 구간추정 (Interval Estimation):
모집단의 모수를 포함할 것으로 예상되는 구간을 제시하는 방법
- 구성 : 신뢰구간(Confidence Interval)과 신뢰수준(Confidence Level)으로 구성
- 신뢰구간 : 모수가 포함될 것으로 예상되는 범위
- 신뢰수준 : 모수가 해당 구간에 포함될 확률
신뢰구간 (Confidence Interval) : 모수가 신뢰구간 안에 포함될 것으로 예상되는 범위
표본을 사용하여 계산하며 구간이 넓을 수록 모수를 포함할 확률이 높아짐
신뢰수준 (Confidence Level) : 모수가 신뢰구간에 포함될 확률
유의수준: a - 모수가 신뢰구간에 포함되지 않을 확률

가설 검정
어떤 추측이나 주장, 가설에 대해 타당성을 조사하는 작업
- 표본 통계량으로 모수 추정 시, 추정한 모수값이나 확률분포 등이 타당한지 평가하는 통계적 추론 방법
귀무가설 (Null Hypothesis, H0) : 버릴 것으로 예상하는 가설
대립가설 (Alternative Hypothesis, H1) : 실제 주장 또는 증명하려는 가설

유의 수준 알파(a):
유의 수준을 0.05로 결정하면
5%의 확률로 귀무가설이 참인데도 불구하고 기각할 가능성을 허용함
1종 오류(Type1 error)
귀무가설이 참인데도 불구하고 이를 기각하는 오류
2종 오류(Type 2 error)
대립가설이 참인데도 불구하고 귀무가설을 기각하지 않는 오류
가설 검정 방법

상관 분석
두 변수 간의 관계를 정략적으로 평가하는 통계 기법
하나의 변수가 변할 대 다른 변수가 어떻게 변하는 지 파악할 수 있음
상관 계수(correaltion coeffcient)
- 두 변수 간의 관계의 강도와 방향을 나타내는 수치
상관관계의 방향
- 양의 상관관계: 한 변수가 증가할 때 다른 변수도 증가하는 경향이 있음
- 음의 상관관계: 한 변수가 증가할 때 다른 변수는 감소하는 경향이 있음
상관관계의 강도
>0.7: 상관계수의 절대값이 0.7이상인 경우 강한 상관관계
0.3< <0.7: 상관계수의 절대값이 0.7이하 0.3이상인 경우 중간 상관관계
<0.3: 상관계수의 절대값이 0.3이하인 경우 약한 상관관계
피어슨 상관계수 (Pearson Correlation Coefficient)
측정 대상 : 연속형 변수 간의 선형 관계를 측정
계산 방법 : 두 변수의 공분산을 각 변수의 표준편차로 나누어 계산
-> 두 변수가 얼마나 함께 변하는지를 표준편차를 통해 정규화한 값
해석
- 𝑟 = 1 ∶ 완전한 양의 상관관계
- 𝑟 = −1 : 완전한 음의 상관관계
- 𝑟 = 0 : 상관관계 없음
장점 : 데이터의 선형 관계를 직접적으로 반영하며, 해석이 직관적
단점 : 두 변수 간의 관계가 비선형 관계일 경우 이를 제대로 반영하지 못함
스피어만 상관계수 (Spearman's Rank Correlation Coefficient)
측정 대상 : 순위형 변수 간의 관계 측정 (비선형 관계일 경우에도 사용 가능)
계산 방법 : 각 변수의 순위를 매긴 후, 그 순위들 간의 상관계수를 계산함 (순위 차이에 따라 값을 계산하므로, 변수 간의 비선형 관계 반영 가능)
해석
- 𝑟 = 1 ∶ 완전한 양의 상관관계
- 𝑟 = −1 : 완전한 음의 상관관계
- 𝑟 = 0 : 상관관계 없음
장점 : 비선형 관계와 이상치에 민감하지 않음
단점 : 데이터의 순위 정보만 사용하여 정보 손실이 발생할 수 있음 (원래 데이터의 크기 정보 등)
켄달의 타우 (Kendall's Tau, Kendall's Rank Correlation Coefficient)
측정 대상 : 변수의 순서 간의 상관성을 측정 (작은 데이터셋에 적합)
계산 방법 : 순위 쌍 간의 일치와 불일치를 비교하여 상관관계를 계산
(일치-불일치)/전체
ex)
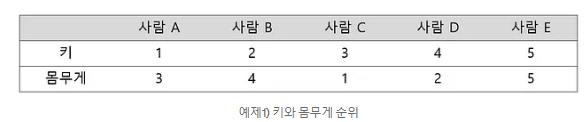
위와 같은 경우 일치하는 것이 사람C-E이므로 (3-2)/5해서 타우가 0.2이다
해석
- 피어슨 상관계수와 동일하게 해석함 (𝜏)
장점 : 순위 정보에 기반하여 비선형 관계도 잘 반영
단점 : 계산이 복잡하며, 해석이 어려울 수 있음 (특히 데이터셋이 클 경우 계산 부담 증가)
MS Azure ML Designer를 활용한 분류 모델
날씨데이터를 활용한 로켓 발사 예측 모델 구현
- MS에서 제공하는 강의 자료를 바탕으로 이론과 실습 진행
- 머신러닝(Machine Learning)의 개념 이해
- 머신러닝 중 분류(classification)에 해당하는 모델 구성
- 로켓 발사 여부 결정을 위한 NASA의 검토 조건(기상 상황) 참고
- 기상 데이터 수집, 머신러닝으로 발사 가능 여부 예측
- 실습 환경 : MS Azure Machine Learning Studio - Designer
머신러닝 개요
인공지능(AI, Artificial Intelligence)
인공지능(AI, Artificial Intelligence): 인간이 가지고 있는 지적 능력을 컴퓨터에서 구현하는 기술
인공지능 발전 요인
- 빅데이터
- 클라우드 컴퓨팅
- 딥러닝 알고리즘
머신러닝
데이터에 기반하여 규칙을 파악하고, 이 규칙에 따라 새로운 입력값의 결과를 예측
- 주어진 데이터를 가장 잘 표현하는 선형 방정식 찾기 - 회귀 모델
- 규칙을 파악하여 예측(ex) 좋아하는 노래 장르를 파악하여 노래 추천, 평소 팝을 좋아했으면 팝을 추천) - 분류 모델
- 유사한 특성을 가진 데이터를 하나의 그룹으로 구분, 그룹에 속해 있다는 정보(정답)이 없음: 주어진 데이터 자체의 특징으로부터 규칙 파악, 주로 거리 개념 사용 - 군집모델
머신러닝 유형
정답 데이터 유무에 따라 지도학습과 비지도학습으로 구분
- 지도 학습: 명시적인 덩답데이터를 가지고 규칙을 찾음
- 회귀: 수치예측(Regression)
- 분류: 범주예측(Classification)
- 비지도 학습: 정답 데이터 없이 규칙을 찾음
- 군집(Clustering)
- 연관(Association)
분류모델 개요
분류(Classification)
분류 알고리즘은 주어진 데이터를 모델에 적용한 후 범주(카테고리) 중 하나의 값으로 분류하여 예측
- 데이터 내에 예측하고자 하는 결과 항목이 명시적으로 표시되어 있음(labeled data)
분류(Classification)는 예측하고자 하는 범주의 개수에 따라 2진 분류와 다중 클래스 분류로 구분됨. 스팸 메일 필터링, 질병 진단 등 다양한 분야에 적용되고 있음
- 서포트 벡터 머신(SVM)
- 의사 결정 나무(Decision Tree)
- 로지스틱 회귀
분류 모델 알고리즘 중 로지스틱 회귀가 있음
서포트 벡터 머신(SVM)
주어진 샘플 데이터들을 구분하는 최적의 분할선 탐

- 위와 같이 분류되었을 때 새로 들어온 데이터와 마진의 벡터값을 측정
- 마진이 넓어야 구분이 잘되었다고 판단
의사결정 나무(Decision Tree)

2클래스 질문에 따라 정답을 찾아 학습하는 알고리즘
머신러닝 용어 및 단계
- 데이터 세트 : 주어진 데이터 전체
- 데이터 샘플 : 개별 데이터
- 데이터 서브셋 : 데이터 일부
- 특성 (feature) :데이터가 가진 개별 특징, 입력 데이터를 테이블 형태로 표시할 때 개별 컬럼(열)에 해당함
- 정답 (label) : 예측하고자 하는 정보범주
- 클래스 (class) : 지도학습 중 분류 알고리즘에서 정답 데이터가 가지는 값의 유형
문제 정의
환경 및 상황 분석
실습 개요 : 날씨 데이터를 수집한 후 머신 러닝을 이용하여 로켓을 발사할지 연기할지 여부를 결정하고자 함
배경-로켓 발사와 날씨
- 최근 전세계적으로 로켓 발사 등의 우주 산업에 대한 관심이 높아지는 추세
- 로켓을 안전하게 발사하기 위해서는 다양한 기상 조건이 충족되어야 함
- 로켓 발사 관련 데이터를 머신러닝 기법으로 분석
->분석 결과를 활용하여 날씨에 따른 로켓 발사 가능 여부를 예측하고자 함
발사 환경
나사(NASA): 미국 항공우주국, 나사는 우주선 발사 등 우주 개발 관련한 일을 맡고 있는 미국의 국가 기관
케이프 커내버럴(Cape Canaveral): 나사는 미국 플로리다 주에 위치한 케이프 커내버럴에서 주로 로켓을 발사함
- 위도가 낮은 플로리다에서 발사된 로켓은 지구의 자전으로 인해 발사 속도 이득이 있으며, 바다 근처에 위치하여 발사 실패 시 민간 지역 피해 최소화 가능
NASA는 사전에 날씨를 분석하여 로켓 발사 날짜 결정, 발사 당일에는 정밀한 우주 비행 관련 기상 분석을 통해 로켓 발사 여부를 결정함
- 미국 해양 대기청과 제 45 공군 기상대의 데이터 참조
유형 및 알고리즘 이해
- 의사결정 나무 사용
의사결정 나무
: 의사 결정 규칙을 나무(tree) 구조로 표현하는 알고리즘
->분류(Classification)를 예측하는 데 주로 사용됨
- weak 알고리즘
수평선/수직선: 의사결정을 위한 질문
- 질문을 통해 산점도를 구획
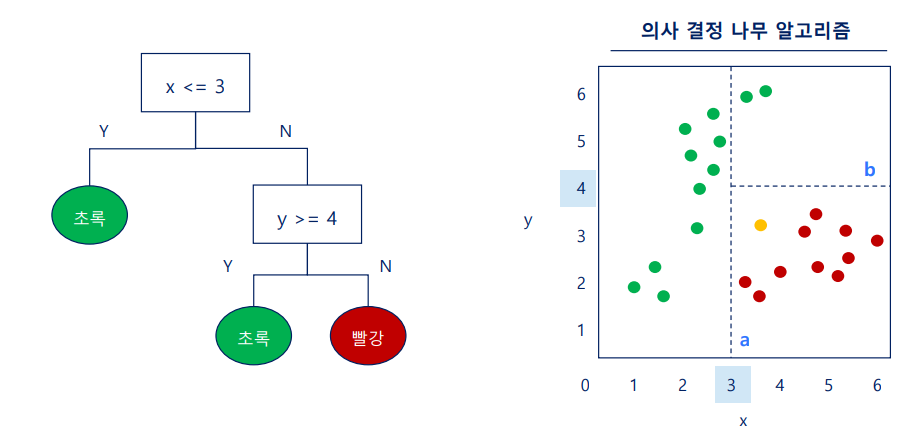
노드는 데이터를 가장 잘 분류할 수 있는 질문, 즉 테스트 조건을 표현
가지(branch)는 테스트 결과를 표현
의사결정 나무- 불순도(impurity)
불순도: 데이터를 가장 잘 분류할 수 있는 테스트 조건(=질문)을 찾아내는 방법
-> 순도가 높아지는 방향으로 구분
- 불순도는 여러 종류의 데이터가 혼합되어 있을수록 높아짐 (불확실성이 높아짐)
- 한 종류의 데이터만 포함되어 있다면 불순도가 낮음
- 여러 종류의 데이터가 포함되어 있다면 불순도가 높음
의사결정 나무- 지니불순도(Gini impurity)
: 의사결정나무의 불순도를 측정하는 기본 지표
각 범주(=클래스)의 비율을 제곱해서 더한 후 1에서 뺀 값으로 계산함
규칙 생성
각 노드의 테스트 조건은 가급적 동일한 범주의 데이터를 모을 수 있도록 정함 (순도가 높도록 정함) = 영향력이 높은 질문(영향력 높은 독립변수)부터 시작함
-> 분리하였을 때 불순도가 낮은 것부터 분리(합산하여)
과대 적합(Overfitting)
의사결정나무는 깊이의 제하닝 없으면 주어진 데이터에 과대적합(overfitting)되기 쉬움
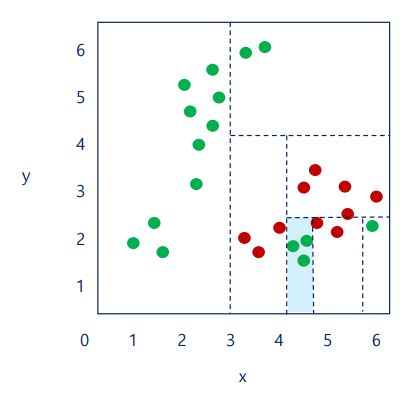
위의 경우, 해당 모델을 초록색으로 판단할 것이다. 그러나, 전체적인 시각으로 보면, 빨간색으로 판단하는 것이 옳다
즉, 주어진 데이터를 잘 설명할 수 있지만 예측력이 떨어지는 경우가 있는데, 이는 과대 적합 때문이다.
-> 불순도가 0이 될 때까지 분리하면 과대적합이 될 수 있다
따라서 의사결정 나무에서는 깊이를 정하여 분리하여 이를 방지하며,
분류 모델은 주어진 데이터 샘플을 활용하여 특정 범주에 속할 확률을 추정할 수 있음
이때, 이 확률의 임계치를 정하여 준다.
예를 들어 빨간 색일 확률이 70%인데 임계치가 90%라면 빨간색으로 판단하지 않는다
모델링 알고리즘 결정
다양한 분류 알고리즘 및 앙상블 기법 등을 검토하여 적용할 알고리즘을 결정
- weak한 알고리즘을 결합하는 것을 앙상블이라고 함
앙상블-랜덤 포레스트
: -여러 머신러닝 모델을 적용
-여러 의사결정 트리를 적요
-> 단순하면서 강력한 분류 알고리즘으로 평가받고 있음
랜덤 포레스트 - 배깅 vs 페이스팅
배깅(Bagging): 샘플링 시 중복을 허용하는 방식
페이스팅(Pasting): 샘플링 시 중복을 허용하지 않는 방식
하이퍼 파라미터(Hyper Parameter)
: 모델링할 떄 사용자가 직접 조정 및 세팅하는 값
ex) 의사결정나무의 깊이, 샘플링 방식 등
데이터 수집/ 이해
데이터 수집
로켓 발사 예측을 위해 접근 가능한 날씨 데이터 수집
미국 해양 대기청 (NOAA)
로켓 발사 장소인 플로리다 지역의 온도 및 바람 관련한 날씨 정보는 미국 해양 대기청에서 수집
- 미국 해양 대기청에서 온도(최고, 최저 및 평균 온도 등), 강수량, 풍향, 풍속 및 최대 풍속 등의 날씨 관련 데이터 수집
웨더 언더그라운드 (Weather Underground)
구름 및 번개 등 추가적인 날씨 데이터는 웨더 언더그라운드 웹페이지에서 수집
Weather History & Data Archive | Weather Underground
Weather History & Data Archive | Weather Underground
Find historical weather by searching for a city, zip code, or airport code. Include a date for which you would like to see weather history. You can select a range of dates in the results on the next page.
www.wunderground.com
- 웨더 언더그라운드는 온도, 강수량, 바람 등의 기본적인 날씨 데이터에 추가하여 과거 온도, 가시거리, 기상 조건(맑음 / 구름 / 번개 등) 정보 제공
NASA
- 나사에서 다양한 우주 탐사 미션을 위한 로켓 발사 데이터 수집
- 1958년부터 2020년 사이에 나사에서 발사한 유인 또는 무인 로켓 발사 기록 총 60건 수집
- NASA가 발사한 당일은 나사가 최적의 날씨로 판단한 것을 가정
즉, 발사 당일 전후 2일간의 날씨 데이터를 추가 -> 이날은 날씨가 좋지 않을 것으로 가정
데이터 이해
수집 데이터 파일 형식
앞서 수집한 데이터를 하나의 파일로 구성(csv)
CSV: 쉼표를 기준으로 항목을 구분하는 데이터 파일
- 수집한 데이터 파일 내의 각 변수의 의미, 형식, 빈 공간 등을 관찰
- 각 컬럼 데이터의 현황(데이터 분포, 평균 등 통계 정보) 확인
데이터 준비
데이터 정리
세상에 존재하는 데이터는 데이터 분석가가 원하는 형태로 정리되어 있지 않음 따라서, 분석가가 원하는 형태로 정제, 변형 등 가공 작업이 요구됨
1) 필요한 컬럼 선택
2) 누락값 처리
3) 데이터 타입 변환 작업 수행
불필요한 칼럼 제외
- 머신러닝 학습에 불필요한 항목 또는 데이터 품질이 낮은 컬럼들을 제외하여 최종적으로 필요한 컬럼만 선택 (Feature Selection)
- 전체 데이터가 누락된 컬럼, 날씨 예측과 관련도가 낮은 컬럼 제외
누락 데이터- 결측치의 처리
일부 값이 누락된 경우 데이터의 의미에 따라 적용할 값을 지정함
유인/무인
누락값 <- Uncrewed
발사여부(Lanched)
누락값 <- N
풍향(Wind direction)
누락값 <- Unknown
기상조건(Condition)
누락값 <- 맑음 Fair
그외
누락값 <- 0
데이터 형식 변경
복잡한 컴퓨터 모델링은 숫자 연산에 더 적합함 범주를 표현하는 문자형 데이터는 범주형 데이터(숫자)로 변경
범주형 문자(열) → 범주형 숫자
범주형 문자(열) → 카테고리 → 숫자
범주형 데이터 간에 순서가 없는 경우 숫자 형식의 데이터를 indicator value로 변환함
1) 컬럼의 데이터 타입을 문자(열)에서 카테고리(범주)형식으로 변환
2) 카테고리(범주)형식을 다시 숫자로 변환하는 과정을 거침
범주형 데이터
-명목형(Nominal): 순서가 없는 범주
-순서형(Ordinal): 순서가 있는 범주
데이터 분리
데이터 세트
지도학습에서는 주어진 데이터를, 데이터의 특징을 나타내는 입력(input, feature)과 예측하고자 하는 정답을 나타내는 타겟(target, label)으로 구분
- 전체 데이터 세트를 학습 데이터와 평가에 사용할 테스트 데이터로 분리
- 전체 데이터 세트를 학습 데이터와 평가에 사용할 테스트 데이터로 분리 시, 무작위 추출(ramdom sampling)을 통해 샘플링 편향(sampling bias)이 최소화 되도록 함
모델링 평가
모델링 유형 및 알고리즘 선택
- 로켓 발사 예측 분석은 과거의 날씨 및 로켓 발사 여부가 포함된 데이터를 기반으로 함. 발사 또는 연기, 2가지 유형으로 예측하므로 머신러닝 중 분류(Classification) 유형으로 결정.
- 다양한 분류 알고리즘 및 앙상블 기법 등을 검토하여 적용할 알고리즘을 결정함
모델링 알고리즘 결정
실습 환경인 Azure Machine Learning은 다양한 모델링 알고리즘을 제공함. 로켓 발사 가능 여부 예측을 위해 2클래스 분류 알고리즘인 의사 결정 포레스트(랜덤 포레스트) 선택

모델링 결과 평가
Azure Machine Learning은 테스트 후 모델을 평가(Evaluate)하는 기능을 제공함
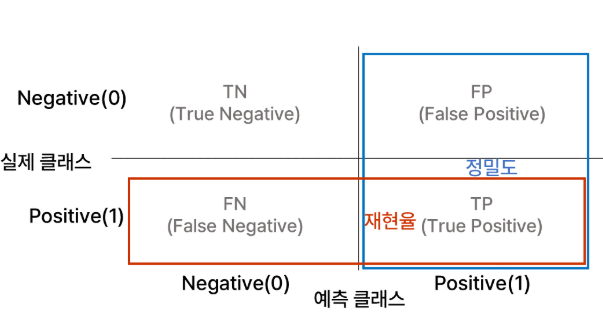
오차 행렬
오차 행렬(Confusion Matrix, =혼동행렬)은 이진 분류의 예측 오류가 얼마인지, 어떠한 유형의 예측 오류가 있는지 확인할 수 있는 지표임
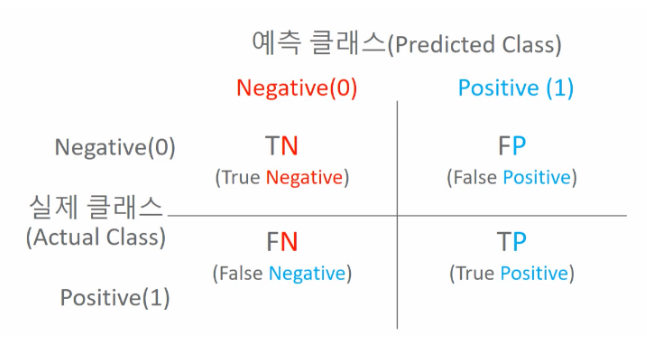
정확도 : 예측값이 실제값과 일치하는 경우의 비율 = 모든 결과 중 모델이 맞춘 비율
TP+TN/전체
정밀도 : 모델이 Positive로 예측한 값 중 실제로 Positive인 비율
TP/TP+FP
재현율 : 실제 Positive인 데이터 중 모델이 맞춘 비율
TP/TP+FN
ex) 암환자가 있다고 할 경우
정밀도가 낮으면: 암이 아닌 사람을 암이라고 진단
재현율이 낮으면: 암 환자를 놓치게 됨
실습
목적
기존 데이터 기준으로 모델 생성 -> 날씨 예보(기존에 없는 데이터) -> 로켓발사에 적합한지 유무 판단
Azure 접속 > 리소스 그룹 안에 ML 생성 > Lanch studio > 우측에 Data> Create
이름, 설명 작성, 유형 - 표형식 > Blob으로 설정하고 데이터 불러오면
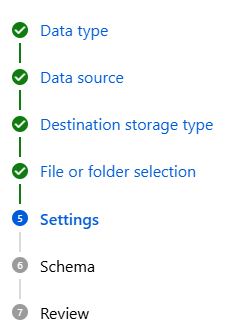
위와 같은 절차들을 따라가면 된다

High Temp, Low Temp, Ave Temp, Hist High Temp, Hist Low Temp, Hist Ave Temp -> Decimal(dot'.')으로 변경
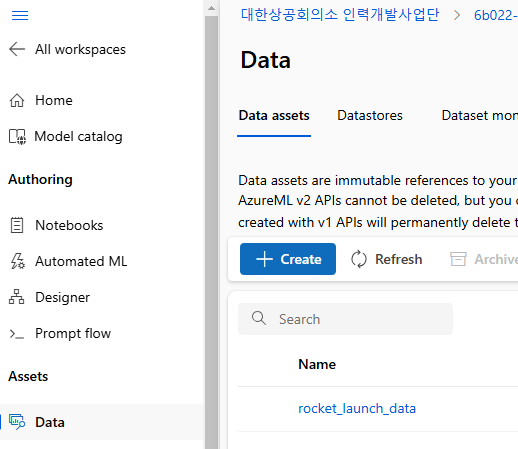
Create하면
Data에 생성이 되었음을 알 수 있다
Manage > Compute> New 해서 컴퓨팅을 새로 생성하면 된다
디자이너 시작
Authoring > Designer > Create a new pipline~
데이터 수집/이해
데이터 세트 가져오기
디자이너에 Data를 드래그앤 드롭으로 가져올 수 있다
해당 아이콘을 더블클릭하면

preview data를 클릭할 수 있는데, 그러면 data를 볼 수 있다
Profile을 누르면 다음과 같이 나온다

데이터 준비
1) 필요한 컬럼 선택
2) 누락값 처리
3) 데이터 타입 변환 작업 수행

필요한 칼럼 선택
Componet > Select Columns in Dataset 드래그앤 드롭
이후, 두 블록을 화살표로 연결한다
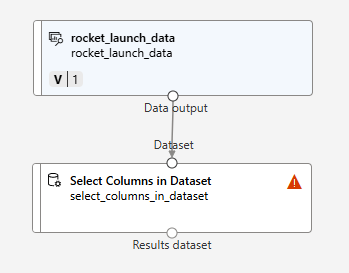
이를 더블클릭하면 다음과 같이 뜬다
Edit column 클릭 > By name
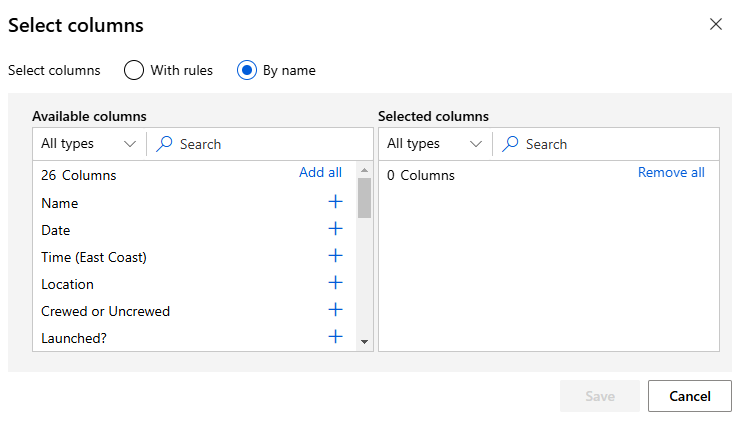
해당창에서 쓸 column을 오른쪽으로 옮기면 된다
아래는 제거할 칼럼 목록이다. 이를 제외하고 저장하면 된다
- Name
- Date
- Time
- Location
- Hist Ave Max Wind Speed
- Hist Ave Visibility
- Sea Level Pressure
- Hist Ave Sea Level Pressure
- Day Length
- Note
누락값 처리
Component > Clean Missing Data >Edit colunm

Uncrewed로 결측값 지정
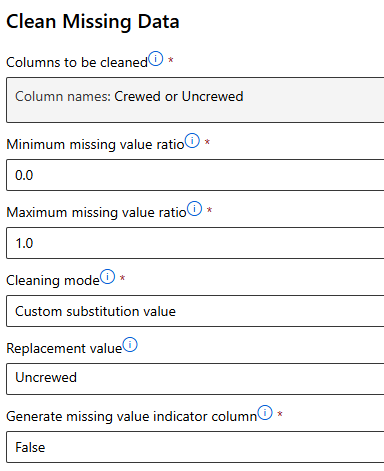
다른 결측값들도 동일하게 진행한다
마지막 컬럼의 경우 즉, 그외 column의 경우에는 All colmns로 설정한다
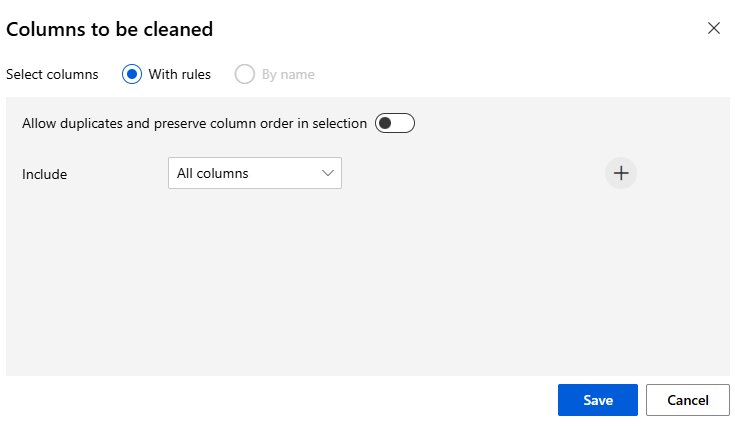
이를 완성하면 다음과 같다

데이터 변환
문자열 데이터 형식을 범주형 데이터로 변경 후, 순서가 없는 범주형 데이터의 경우 indicator value로 변환
1) 컬럼의 데이터를 String 형식에서 Category(범주) 형식으로 변환한 후,
2) Category(범주) 형식을 다시 지시값 형식으로 변환하는 과정
String → Category(범주)

Component > Edit Metadata 선택 후 Crewed or Uncrewed, Wind Direction, Condition 열을 Categorical로 변경
Category(범주) → 숫자

Component > Convert to Indicator Values 선택 후 Crewed or Uncrewed, Wind Direction, Condition 열을 overwrite를 True 로 지정

여기까지 완료하면 구성이 위와 같이 나온다
이후, 커퓨팅 리소스가 켜져 있는 지 확인 후, Designer 우측 상단의 > Configure & Submit 버튼을 누른다

Create new > New experiment name
이름 지정 후 아래의 창에서 compute instance를 정해주어야 한다
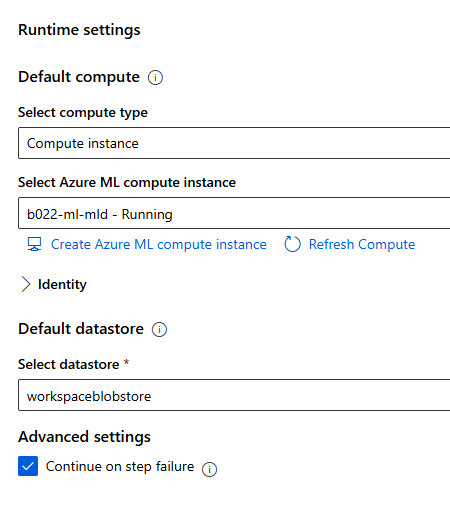
중간 점검: 현재까지 작성 내용 실행
우측 탭의 Jobs를 클릭하면 아래와 같은 화면이 실행된다ㄴ

로딩하는 데 다소 시간이 거릴 수 있으므로 유의한다.
상단의 View profiling 메뉴를 통해 실행 중인 파이프라인의 상세 진행 상황이 확인 가능하다
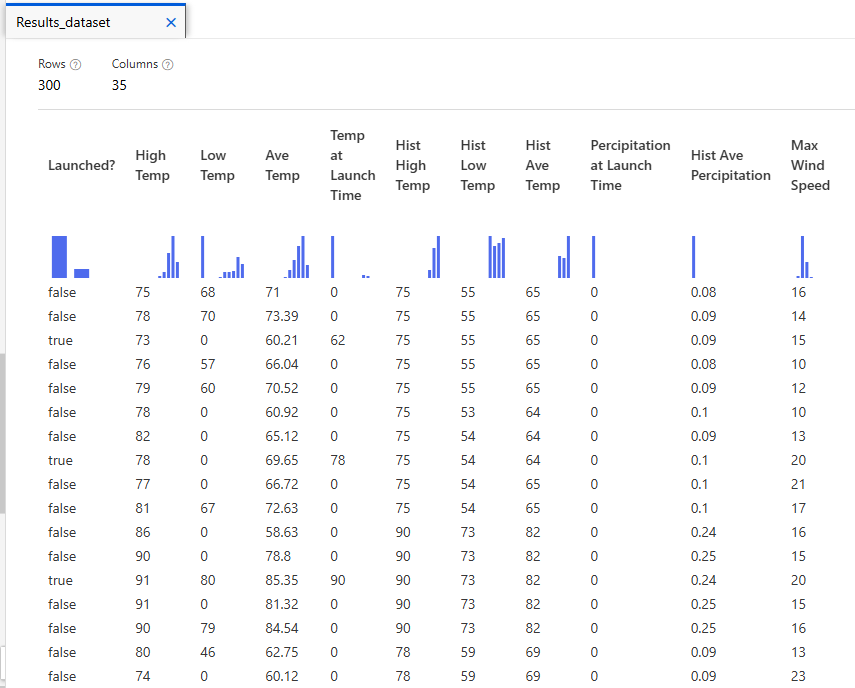
Jobs 파이프라인의 마지막 컴포넌트 (여기서는 Convert to Indicator Values) 우측 마우스 클릭 >
Preview data > Result dataset
-> 지금까지의 데이터 정리 작업이 적용된 결과가 표시된다
오늘의 간단한 후기
블록 스타일의 코딩을 처음해 보아서 익숙치 않았다. 그래도 Designer tool을 처음으로 써보고 접할 수 있어서 좋았다. 데이터 구조를 시각적으로 파악하는 데에 유용할 것 같았다. 그러나, 처음 말고는 column 이름을 직접 쳐야 한다는 점이 번거로웠다. 나중에 개선을 하게 된다면 select 된 열들 중에서 고를 수 있는 기능을 추가했으면 좋겠다. 마지막에 속도가 조금 빨라서 버거웠지만 강의 교안이 잘 되어 있어서 따라갈 수 있었다. 새로운 tool을 써보는 것이 보람있었다
출처
[1] 권오흠, *팩트풀니스*. Google 도서, [Online]. Available: https://www.google.co.kr/books/edition/%ED%8C%A9%ED%8A%B8%ED%92%80%EB%8B%88%EC%8A%A4/_nUbEQAAQBAJ?hl=ko&gbpv=1&pg=PT2&printsec=frontcover. [Accessed: Jan. 16, 2025].
[2] Gapminder, "Gapminder Tools," *Gapminder*. [Online]. Available: https://www.gapminder.org/tools/#$chart-type=bubbles&url=v2. [Accessed: Jan. 16, 2025].
[3] Ingentive, "Build Your Microsoft Azure Predictive Model," *Ingentive*. [Online]. Available: https://www.ingentive.com/build-your-microsoft-azure-predictive-model/. [Accessed: Jan. 16, 2025].
[4] Tistory, "대표값," *Thanks Blog*. [Online]. Available: https://thanksblog.tistory.com/entry/%EB%8C%80%ED%91%9C%EA%B0%92-1. [Accessed: Jan. 16, 2025].
[5] Extreme Presentation, "Chart Chooser 2020," *Extreme Presentation*. [Online]. Available: https://extremepresentation.typepad.com/files/chart-chooser-2020.pdf. [Accessed: Jan. 16, 2025].
[6] Tistory, "기계 학습에서의 과적합(Overfitting) 방지 방법," *Cloud's Daily*. [Online]. Available: https://clouds-daily.tistory.com/12. [Accessed: Jan. 16, 2025].
[7] Tistory, "RNN(LSTM) 실습 예제," *HSM Edu*. [Online]. Available: https://hsm-edu.tistory.com/147#google_vignette. [Accessed: Jan. 16, 2025].
[8] 이주경, "켄달타우(Kendall Tau)," *Medium*. [Online]. Available: https://medium.com/@leejukyung/%EC%BC%84%EB%8B%AC%ED%83%80%EC%9A%B0-kendalltau-18fb90ba4e7. [Accessed: Jan. 16, 2025].
[9] 네이버 블로그, "딥러닝의 역사와 발전 과정," *네이버 블로그*. [Online]. Available: https://m.blog.naver.com/winddori2002/221662413641. [Accessed: Jan. 16, 2025].
[10] Weather Underground, "Weather History & Data Archive," *Weather Underground*. [Online]. Available: https://www.wunderground.com/history. [Accessed: Jan. 16, 2025].
[11] Microsoft, "Machine Learning Algorithm Cheat Sheet," *Microsoft Learn*. [Online]. Available: https://learn.microsoft.com/ko-kr/azure/machine-learning/algorithm-cheat-sheet?view=azureml-api-1. [Accessed: Jan. 16, 2025].
[12] Tistory, "머신러닝에서의 교차 검증(Cross Validation) 방법," *Yarisong Blog*. [Online]. Available: https://yarisong.tistory.com/82. [Accessed: Jan. 16, 2025].
[13] Microsoft Azure, "Microsoft Azure: Cloud Computing Services," *Microsoft Azure*. [Online]. Available: https://azure.microsoft.com/. [Accessed: Jan. 16, 2025].
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(강명호 강사님)을 기반으로 제작되었습니다
깃허브 소스코드의 내용을 담고 있습니다
Microsoft에서 제공하는 Dataset을 포함하고 있습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다