[Microsoft AI School 6기] 1/17(22일차) 정리 - MLD, 분류 모델, 회귀 모델, 군집 모델 실습
MS Azure ML Designer를 활용한 분류 모델
날씨데이터를 활용한 로켓 발사 예측 모델 구현
데이터 준비
데이터 분리
Designer > Component > Split Data > 드래그앤 드롭 후 더블 클릭

왼쪽을 학습데이터로 사용, 학습데이터를 70%로 지정
테스트 데이터는 30%로 분리
- split rows: 행 = 데이터 샘플
- Randomized split: 행 기준 무작위로 분리
- Random seed: 난수 초기값 ex) 0으로 하면 다 결과가 동일하게 나타남 즉, 확인 가능
모델링/평가
모델링 알고리즘 선택
-> Two-Class Decision Forest
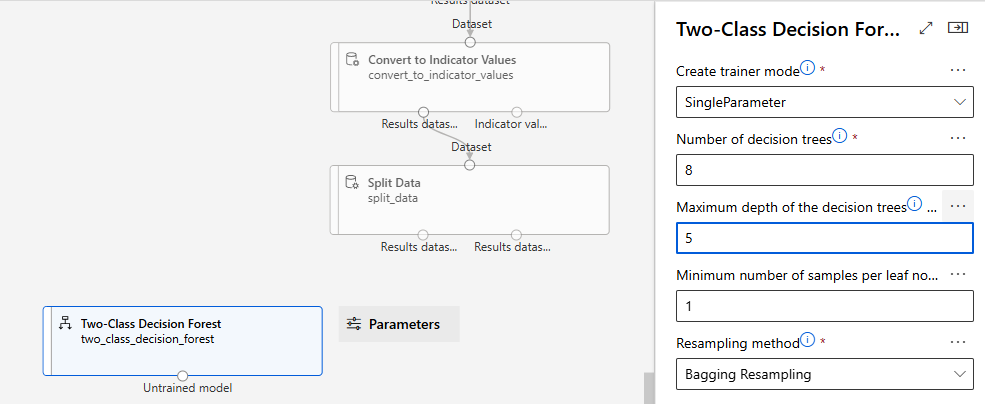
Bagging Resampling
- 샘플링 시 중복 허용, 복원 추출
의사결정 나무의 깊이: 5
의사결정 나무 개수: 8
리프노드에 포함해야할 최소 샘플의 개수: 1
모델 학습(훈련)
모델 훈련 (Train Model) component 선택
- 모델 훈련을 위해
1) 학습 데이터세트 및 2) 어떤 알고리즘을 적용할 지 여부가 필요
- Split Data의 좌측 (학습 데이터 - 70%)와 2-클래스 Decision Forest 모델을 입력 값으로 적용
분류 모델에서는 정답(라벨, Label)으로 사용할 컬럼을 지정해야 함
- 로켓 발사 여부를 나타내는 Launched? 컬럼을 Label 컬럼으로 지정

모델 테스트
테스트 결과를 산출하는 모델 테스트 (Score Model) 컴포넌트를 캔버스로 이동
생성한 훈련 모델 및 테스트 데이터를 각각 선으로 연결하여 입력 값으로 사용
모델 테스트를 위해
1) 테스트 데이터세트 및 2) 훈련된 모델이 필요
- Split Data의 우측 (테스트 데이터)과 훈련이 끝난 Trained Model을 입력 값으로 적용
- 30%의 테스트 데이터 사용

모델 평가
테스트 결과를 평가하는 모델 평가 (Evaluate Model) 컴포넌트를 캔버스로 이동
앞 단계에서 산출한 Scored dataset을 선으로 연결
- 앞 단계에서 산출한 테스트 결과를 가지고 모델 평가

Review and submit

Select existing으로 설정하고 submit
정밀도와 재현율

오차 행렬의 이해
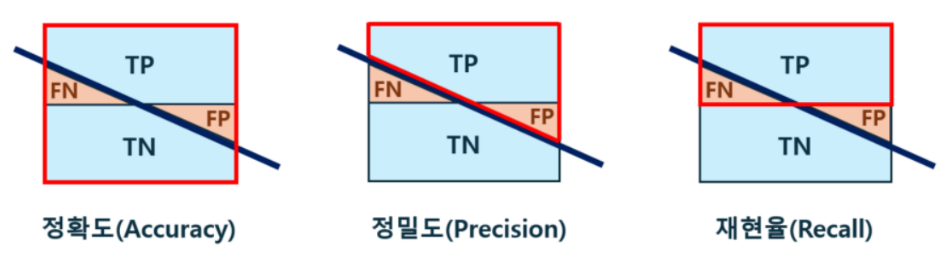
True positive rate = 재현율
ROC Curve
ROC Curve : True positive rate과 false positive rate의 관계 – 모든 임계값에서 분류 모델의 성능 표현

모든 임계값에서 성능 표현
- 대각선은 Random Classifier
실행 후 결과 확인- 모델 테스트 결과
Jobs > Score Model 우측 클릭 > Preview data > Scored dataset

위의 결과를 확인하면 다음과 같은 과면이 떠서 Scored Lables의 결과를 확인할 수 있다
테스트 결과에 로켓 발사 가능 여부와 예측 확률이 표시된다

실행 후 결과 확인 - 모델 평가 결과
Jobs > Evaluate Model 우측 클릭 > Preview data > Evaluation results

위의 경로로 들어가면 아래의 결과를 볼 수 있다
정확도 (Accuracy)를 포함한 다양한 모델 평가 결과가 표시된다

대각선이 있다고 가정하고 보면 결과를 ROC Curve를 기준으로 상위로 데이터가 구성되어 있어 성능이 매우 좋음을 알 수 있다.
- 임계값을 변경해가며 예측값의 변화를 확인할 수 있음
-> 임계값을 기준으로 True, False를 판단
ex) 해당 분류의 70% 이상이 초록색이면 초록색으로 판단, 그 미만은 빨간색으로 판단
ROC curve, Precision-recall curve, Lift curve는 변화하지 않음(임계값 상관 X)
MS Azure ML Designer를 활용한 회귀 모델
날씨데이터를 활용한 로켓 발사 예측 모델 구현
- MS에서 제공하는 강의 자료를 바탕으로 이론과 실습 진행
- 자전거 렌탈 수요에 영향을 미치는 요인 파악
- 다중 선형 회귀 알고리즘으로 자전거 렌탈 수요 예측
- 머신러닝 중 회귀(regression)에 해당하는 모델 구성
- UCI dataset 활용
- 실습 환경 : MS Azure Machine Learning Studio - Designer

문제 정의
환경 및 상황 분석
자전거 수요에 영향을 미치는 요소
- 날씨
- 계절: 봄과 가을은 자전거 이용에 긍정적인 영향을 주고, 여름과 겨울은 부정적인 것으로 나타남
- 휴일/평일
모델링 주제
- 자전거 렌탈 데이터를 머신러닝으로 모델링하여 자전거 수요 예측
- 날씨, 계절과 휴일 여부에 따른 자전거 렌탈 수요를 예측함
자전거 렌탈 데이터 -> 자전거 렌탈 수요 예측
모델링 유형
- 회귀: 수치예측(Regression) 모델 사용
자전거 수요량은 특정 조건에서 수치형 데이터를 예상하는 것이므로 머신러닝 유형 중에서 회귀
-> 회귀에서도 여러 조건을 고려해야 하므로 다중 회귀에 해당
다중 회귀: 여러 변수 -> 종속 변수 예상
회귀 알고리즘 이해
회귀
회귀는 ‘옛날의 대표적인 자리(평균)로 돌아간다‘는 의미 (데이터를 대표하는 값 찾기)
= 예측한 선으로 오차가 회귀(regression)하도록 만들어진 모델
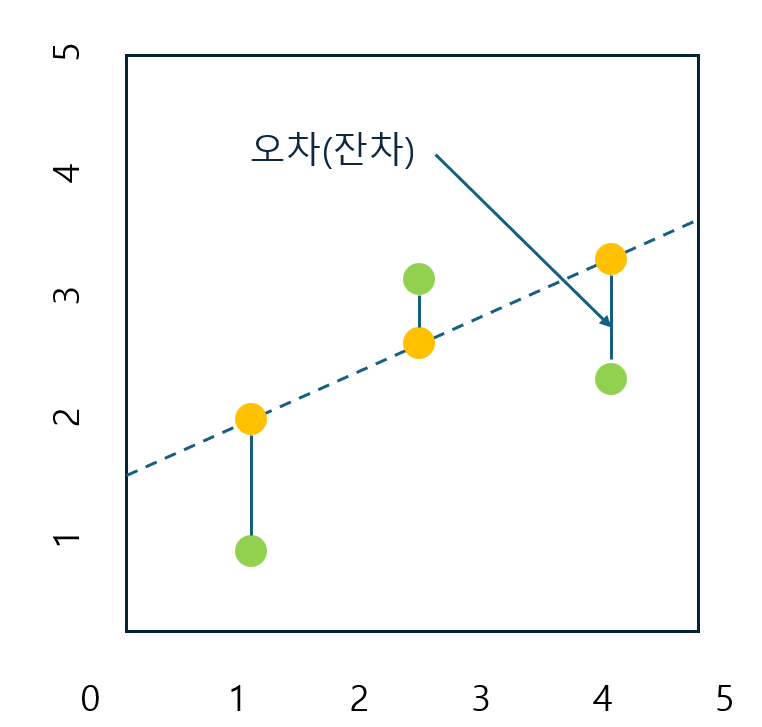
오차(잔차): 데이터의 실제값 - 모델의 예상 값

오차들은 정규분포를 따르고 평균은 0이라 가정
선형 회귀(Linear Regression)
선형 모델은 회귀 계수를 선형 결합으로 표현할 수 있는 모델을 의미
선형 회귀는 독립변수와 종속변수의 관계를 선형 관계로 모델링하며, 간단하고 해석이 용이함.
- 오차가 정규분포를 따라야 선형회귀 방법을 쓰는 게 적절
단순 선형 회귀
회귀(Regression) 알고리즘은 입력 값에 대응하는 임의의 연속적인 수치를 예측.
선형 회귀 : 주어진 데이터의 특성을 가장 잘 나타낼 수 있는 선형식을 학습하는 알고리즘
독립변수 𝑥 로부터 종속변수 𝑦 를 예측하는 알고리즘

- 𝑥 : 독립변수, 𝑦 : 종속변수
- 𝑤 : 기울기, 계수(coef), 가중치(weight)
- 𝑏 : 절편(intercept), 편향(bias)
선형 회귀에서 발생하는 오차, 손실(Loss)
선형 회귀 모델의 목표 : 오차를 최소화할 수 있는 기울기와 절편 찾기
오차(손실) = 실측값과 예측값의 거리
- 오차 (실측값과 예측값의 거리) 계산 : 실측값 - 예측값

오차가 양수/음수 관계 없이 동일하게 반영되도록 제곱을 해주거나 절댓값을 취함
-> MSE, MAE
머신러닝에서의 거리(distance)
머신러닝에서의 거리(distance) 개념은 데이터 간의 유사도(similarity) 및 손실(loss)을 계산할 때 자주 사용됨
좌표에서 두 점 사이의 거리가 가깝다는것은 위치가 유사하다는 의미 → 거리 공식은 손실함수로 사용 가능

비용함수 – MAE (Mean Absolute Error)
오차의 절대값을 평균한 값 (L1 Loss)
MAE가 0에 가까울수록 예측값이 실측값과 가까움

- 오차의 단위가 label과 동일함
- MAE는 회귀 모델의 평가지표로 사용됨
- 특이값 (이상치, outlier) 의 영향을 덜 받음
- L1 distance
비용함수 – MSE (Mean Squared Error)
오차의 제곱을 평균한 값(L2 Loss) : MSE가 0에 가까울수록 예측값이 실측값에 가까움.
예측값과 실측값 차이를 한 변으로 하는 정사각형 면적의 평균과 같음

- 회귀 모델에서 비용함수로 사용됨
- 값을 제곱함 → 작은 오차는 더 작아지고, 큰 오차는 더 커지는 왜곡 발생
- 따라서, 특이값(이상치, outlier)의 영향을 많이 받음
- 모든 함숫값에서 미분 가능
- L2 distance
다중 선형 회귀 (Multiple Linear Regression)
종속변수 𝑦가 여러 독립변수 𝑥1, 𝑥2, 𝑥3, …에 의해 영향을 받는 경우에 사용
하나의 결과를 여러 원인으로 설명할 수 있음
- 독립변수 중 종속변수를 설명하는데 필요한 변수만 모델에 포함시켜야 함
중요한 독립 변수를 포함시키는 방법
1) 전진선택법 (Forward Selection) : 독립 변수를 하나씩 추가하면서 모델을 만들고 결과 확인
2) 후진제거법 (Backward Elimination) : 데이터에 있는 모든 독립 변수를 사용해 모델을 만들고 하나씩 제거한 후 결과 확인
데이터 수집/이해
데이터 수집
자전거 렌탈 데이터 수집
UCI에서 제공하는 데이터에 기반하여 자전거 렌탈 수요 예측을 위한 모델을 구현
[참고]
우리나라에서는 서울시 열린데이터 광장에서 따릉이 대여 정보 등 공공자전거 데이터를 수집할 수 있음 *
- 엑셀을 이용하여 CSV file을 확인할 수 있음
데이터 이해
자전거 렌탈 데이터 세트 확인
- day – 관찰이 이루이진 날짜
- mnth – 관찰이 이루어진 월
- year – 관찰이 이루어진 년도
- season – 계절 (1: 겨울. 2: 봄, 3: 여름, 4: 가을)
- holiday – 공휴일 여부 (1:공휴일, 0: 공휴일아님)
- weekday – 요일 (0:일, 1:월, 2:화, 3:수, …, 6:토)
- workinday – 근무일 여부 (1:근무일, 0:근무일 아님)
- weathersit – 날씨 상황
- Clear, Few clouds, Partly cloudy, Partly cloudy
- Mist+Cloudy, Mist+Broken clouds, Mist+Few clouds, Mist
- Light Snow, Light Rain+Thunderstorm+Scattered clouds, Light Rain+Scattered clouds
- Heavy Rain+Ice Pallets+Thunderstorm+Mist, Snow+Fog
- temp, atemp – 온도와 체감 온도
- hum - 습도 • windspeed – 바람의 세기
- rentals – 자전거 대여수 – 라벨(타겟)
데이터 준비
데이터세트 등록
Azure machine Learning Studio > Assets|Data> Create > 실습 파일 등록
컴퓨팅 대상 설정: Compute Cluster

실습 환경 : Compute clusters
컴퓨트 대상 : 머신러닝을 실행할 수 있는 컴퓨팅 자원
-> 여러 유형의 컴퓨팅 대상 중 컴퓨트 클러스터를 선택하여 생성
컴퓨트 클러스터는 모델 학습과 평가를 지원하는 확장 가능한 가상 머신

이후 생성이 완료되면
컴퓨트 클러스터가 생성 -> 'Succeeded'로 상태(state)가 변경되며, 생성 초기 노드 수는 0임

머신러닝 디자이너 선택
Designer > Create > 이름 변경
데이터 세트 가져오기
데이터 세트
Designer > Data > 실습 데이터 가져오기
드래그앤 드롭을 가져오고 더블 클릭
>Outputs를 누르면 아래와 같은 화면이 나온다

범주형 테이터
mnth, season, holiday, weekday, workingdat, weathersit
수치형 데이터
temp, atemp, hum, windspeed, rentals
-> temp 정규화 되어 있음
> Profile 클릭

Min, Max, 누락값 확인
Execute Python Script - Heatmap 그리기
Execute Python Script Component 추가

더블클릭하면 파이썬을 입력할 수 있는 script가 뜬다
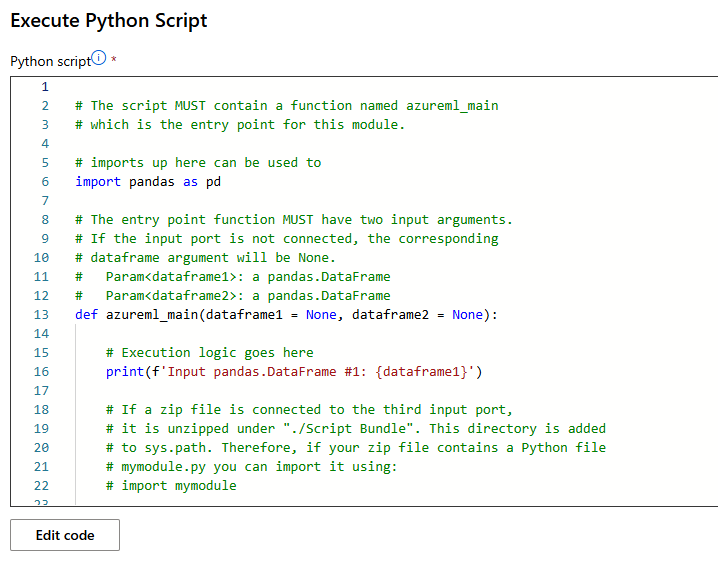

위와 같은 코드를 입력하면 그래프를 그려준다,
heatmap.png 파일로 이미지가 생성되어 graphics/heatmap.png 로 graphics 아래에 저장된
> save 후 > Configure and submit > Create new하면 아래 창이 뜬다


Runtime settings에서 사용할 compute type과 ML을 정해주고 submit을 누르면 된다
Heatmap 결과 확인
Jobs > Execute Python Script 블록 더블 클릭 > Outputs + logs> graphics 아래에 heatmap.png가 있음을 확인할 수 있다

heatmap.png는 다음과 같이 나온다

상관 관계가 있는 것을 찾아낼 수 있다. 즉, 종속 변수와 상관관계가 낮은 것들을 제외하고 결과를 내는 것이 좋다
특성 선택
특성(feature)으로 사용할 열 선택
Designer > Select Columns in Dataset 컴포넌트를 사용하여 특성으로 사용할 컬럼을 선택

> 우측 상단 Edit column 클릭

day, years 빼고 선택하여 실습 진행
누락값 처리
Missing count를 처리하면 되는 데 해당 실습 파일에서는 누락값이 없으므로 생락한다
범주형 데이터 변환
메타데이터 변경 : 정수형 범주값 → 카테고리형
컬럼의 데이터타입이 정수형을 가지는 명목형 범주값을 카테고리형으로 변환함
> Edit Metadata Component 이용
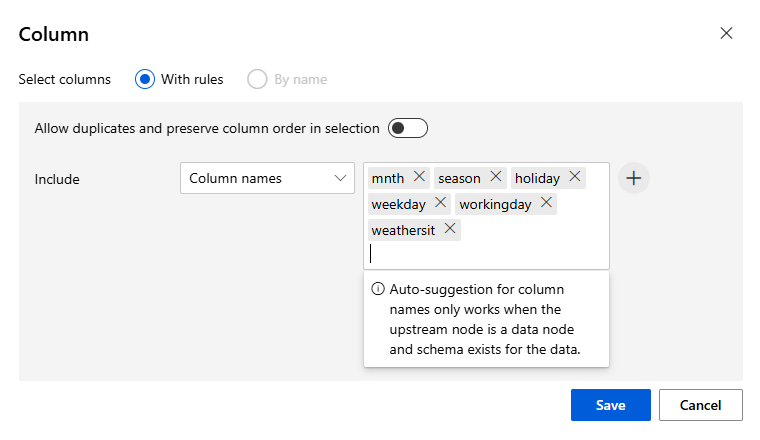
원하는 데이터 칼럼을 선택하여 Categorical로 변경

범주 데이터 변환 : 지시값 할당 – One-Hot encoding
범주(category)에 고유한 순서나 가중치 부여 등을 방지하기 위해 원핫(One-hot) 인코딩 사용

- 순서관계 제거
> Convert to Indicator Values Component 사용

표준화와 정규화
정규화(Normalization) : 범위 또는 단위가 다른 값들을 [0, 1] 사이의 값들을 갖도록 변환
- 값의 범위가 다름 -> 정규화 필요
ex) 키와 몸무게
표준화(Standardization) : 평균이 0, 표준편차가 1이 되도록 값들을 변환 (표준정규분포)
- 값의 분포가 다름-> 표준화 필요
ex) 평균이 20점인 시험과 80점인 시험에서의 50점 받은 학생
Categorical 데이터는 수치 데이터가 아니기 때문에 정규화, 표준화를 하지 않음
- 범주형 데이터는 값 간의 순서가 없기 때문에 정규화, 표준화 X
수치형 데이터에 정규화, 표준화 진행
> Normalize Data Component 사용
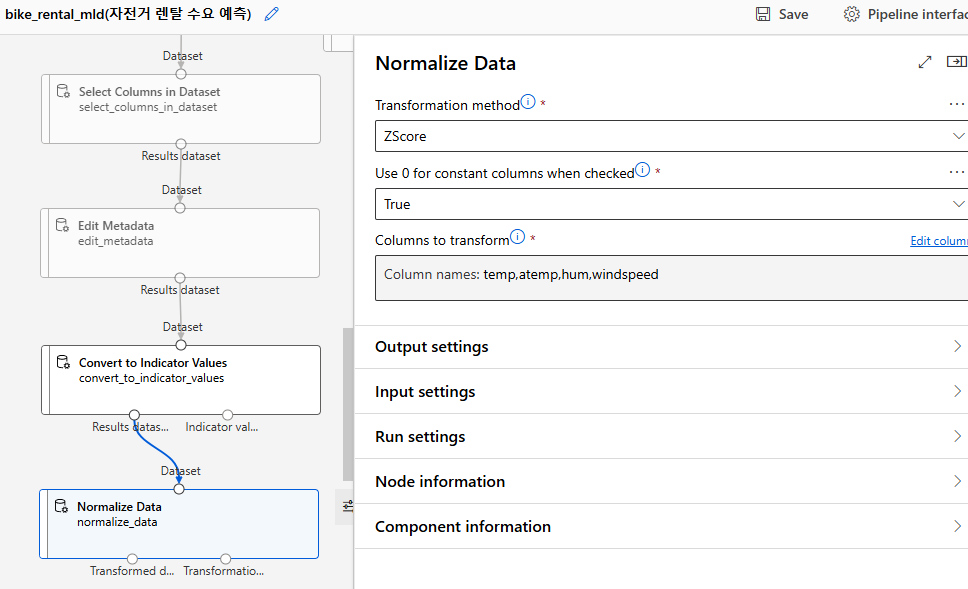
- 수치형 데이터 : temp, atemp, hum, windspeed
에 정규화 진행
중간 점검: 현재까지 작성 내용을 실행
> Designer > Configure & Submit > Select existing > Submit
> Computing
- Computing 확인
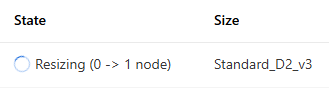
Node가 늘어나면서 computing을 사용하는 것을 확인할 수 있음
> Jobs > 마지막 노드인 Normalize Data 우측 마우스 클릭 > Preview data > Transformed dataset

데이터 분리
학습 데이터와 테스트 데이터로 분리
> Designer >Split Data Component 선택
앞 단계의 Results datasets를 입력 값 사용, 데이터 분리 컴포넌트에 선으로 연결

Split Data 블록의 왼쪽 연결을 학습데이터(70%), 오른쪽을 테스트 데이터(30%)로 사용할 예정
모델링
선형회귀 모델 학습 과정
선형 회귀 모델의 학습 과정

Input 데이터 학습 -> Model에서 w와 b값을 학습
즉, w와 b값을 찾는 것이 목표
기울기를 줄일 수 있는 방향으로 학습
Epoch: 데이터세트를 한번 학습
경사하강법 (Gradient Descent)
모델은 비용함수(cost function)를 사용하여 오차를 줄이는 방향으로 학습.
경사하강법을 통해 오차가 최소가 되는 방향으로 가중치를 조정(update)해 가며 학습

- 경사(Gradient)가 감소하는 방향으로 가중치를 조정하면 오차율이 최소인 지점을 찾을 수 있음
학습율은 보폭, 기울기는 방향

비용 함수에서 경사가 주는 방향으로 가면 손실이 0인 지점을 찾을 수 있을 것이라 예상
즉, 예를 들어 처음 미분한 지점이 5이면, 5만큼 감소한 곳에서 미분 ->이곳의 기울기가 1이면 1민큼 감소한 곳에서 미분 ...이런식으로 하면 기울기 0 인 지점을 찾을 수 있을 것이라 생각 -> 오차가 최소가 되는 방향으로 나아감
아래 링크 참조
데이터 과학 및 머신 러닝(파트 06): 경사 하강법(Gradient Descent) - MQL5 기고글
데이터 과학 및 머신 러닝(파트 06): 경사 하강법(Gradient Descent)
경사 하강법은 신경망과 여러가지 머신러닝 알고리즘을 훈련하는 데 중요한 역할을 합니다. 경사 하강법은 인상적인 작업을 하면서도 빠르고 지능적인 알고리즘입니다. 많은 데이터 과학자들
www.mql5.com
단점: local minia에 빠질 수 있음
-> momentum이용하는 방법이 있음
선형 회귀는 이차함수로 나오기 때문에 local minia의 단점이 존재하지 않음
학습률 (Learning Rate)
경사 하강법은 기울기에 학습률(보폭)이라는 스칼라 값을 곱해서 다음 지점을 정함
최적점에 도달하기 위해서 적절한 학습률을 설정하는 것이 중요
학습률: 보폭
- 학습률이 큰 경우 - 빠르게 학습할 수 있으나 최적점을 벗어날 수 있음
- 학습률이 작은 경우 - 최적점에 도달하기에 너무 오랜 시간이 걸림

수렴 (Convergence)
선형 회귀 분석은 비용함수 및 경사하강법 등을 이용하여 회귀계수(기울기와 절편)의 최적값을 찾아 나감 기울기와 절편을 반복하여 update(학습)하면 특정 값으로 수렴(converge)함
ex) 800번 이상 반복 했을 때 회귀계수(기울기아 절편)이 유의미하게 좋아지지 않음
규제
과대적합(Overfitting) vs 과소적합(Underfitting)

과소적합 : 최적화가 제대로 수행되지 않아 학습 데이터의 구조와 패턴을 정확히 반영하지 못함
최적의 모델 : 충분한 학습 데이터로 과소적합을 막고, 규제를 적용하여 과대적합이 되지 않도록 함
과대적합 : 학습 데이터를 지나치게 학습하여 학습 데이터에서는 성능이 좋으나 테스트 데이터에서 성능이 떨어짐
규제 (Regularization)
다중 회귀 모델 : 독립변수가 많아지면 과대적합의 경향이 있음
규제 : 회귀식의 가중치의 영향력을 제한하여 과대적합을 방지함
𝑦 = 𝑤1𝑥1 + 𝑤2𝑥2 + ⋯ + 𝑤𝑛𝑥𝑛 + 𝑏 -> 𝑤1 , 𝑤2 , … , 𝑤𝑛 의 크기(양)에 패널티 부여

L1규제 : LASSO(라쏘)
L2 규제: Ridge(릿지)
알고리즘 및 하이퍼 파라미터
회귀 - 선형 회귀 사용
- 선형 회귀의 학습을 위해 경사하강법(Grandient Descent) 사용
- SignleParameter : 하이퍼파라미터를 하나씩 설정하여 학습
- ParameterRange : 여러가지 하이퍼파라미터를 조합하여 학습 (시간 오래걸림)
- learning rate: 경사하강법의 학습률
- epochs 전체 학습 데이터를 학습 시키는 횟수
Designer > Linear Regression component

모델 학습
Designer > Train Model component

평가
모델 테스트
테스트 데이터로 모델 점수 매기기(score model)
테스트 데이터로 만들어진 자전거 수요예측 모델이 제대로 예측하는지 점수를 매김.

모델 평가
여러 평가지표(Metrics)로 모델을 평가하는 ‘Evaluate Model’을 드래그 앤 드롭한 후, 전체를 수행

> Configure & submit > Review +Submit
평가 지표
오차(손실)
MAE (Mean Absolute Error)
- 오차의 절대값을 평균한 값
- 독립변수의 단위 유지
RMSE (Root Mean Squared Error)
- MSE의 제곱근 : 오차의 제곱을 평균한 값의 제곱근
- 이상치에 민감함
RAE (Relative Absolute Error)
RAE : MAE(Mean Absolute Error)를 실제값과 평균값의 절대차의 평균으로 나눈 값
RAE가 0에 가까울수록 예측값이 실측값과 가까움
- 예측값의 평균과 단위에 민감하지 않음
- 따라서, 다른 단위로 오류가 측정되는 모델과의 비교에 사용됨
- 이상치에 민감하지 않음
-> 상대적으로 비교하기 위한 값
0-1사이의 값
RSE (Relative Squared Error)
RSE : MSE(Mean Squared Error)를 실제값과 평균값의 차이의 제곱평균으로 나눈 값
RSE가 0에 가까울수록 예측값이 실측값과 가까움
- 예측값의 평균과 단위에 민감하지 않음
- 따라서, 다른 단위로 오류가 측정되는 모델과의 비교에 사용됨
- 이상치에 민감함
0-1사이의 값
결정계수 R^2 : Coefficient of Determination
- 모델의 독립변수들이 종속변수를 얼마나 잘 설명하는지 나타내는 지표
-> 모델이 데이터를 얼마나 잘 설명하는가
종속변수의 변동량 중에서 회귀모델로 설명가능한 부분의 비율
즉, 결정계수는 독립변수가 종속변수를 설명하는 정도를 표현하는 지표 (설명력)



R^2의 값에 따라 모델이 얼마나 데이터를 잘 나타내는 지를 표현할 수 있다
예측 결과 확인
> Jobs
Scored Labels 확인
학습된 머신러닝 모델이 예측한 rentals 레이블 값 및 통계정보 확인

rental 열이랑 scored를 비교
rental은 정답, scored는 ml이 학습하여 예측한 값
Evaluation results 확인

R^2는 0.7을 넘는 것이 좋음
-> R값이 부족하면 epochs를 늘리는 방법이 있음
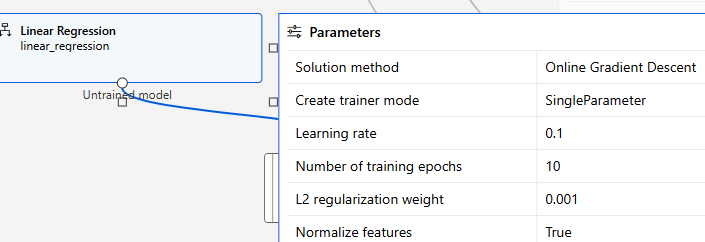
- 여기에서 epoch 수를 늘리는 것도 방법임
MS Azure ML Designer를 활용한 군집 모델
프로야구 데이터를 활용한 선수능력 측정 모델 구현
- “한국프로야구에서 타자능력의 측정“ 논문에 언급된 이론과 실습 진행
- 프로야구 선수능력 평가지표인 세이버메트릭스 데이터 수집
- K-means 군집 알고리즘 및 PCA(주성분 분석) 차원축소 개념 확인
- ML Studio의 Designer 및 외부 코드 연동을 이용한 실습
- 실습 환경 : MS Azure Machine Learning Studio Designer – Python
문제 정의
야구 타자의 능력 수치를 바탕으로 내년 스카웃 결정
환경 및 상황 분석
관련 논문
이장택, “한국프로야구에서 타자능력의 측정”, 한국데이터정보과학회지, 2014, 25(2), 349–356
Statcast
메이저리그에서는 2015년 부터 Trackman과 Chyron hego Camera를 활용하여 야구 경기에서 발생하는 다양한 데이터를 수집하는 Statcast를 운영 (30개 메이저리그 구장 도입)
Traditional stats의 문제점
Traditional stats : 오래 전에 사용된 지표.
야구의 규칙에 많은 변화 선수 개인의 평가에 적합하지 않은 지표들도 다수 존재함
Sabermetrics
야구를 통계학적/수학적으로 분석하는 방법론
Traditional Stats이 가지고 있는 문제점을 보안하기 위해 만들어진 지표들 (매우 다양함
- OPS (On base percentage plus slugging percentage) (On base percentage plus slugging percentage)
- ISO (Isolated Power)
- SecA (Secondary Average)
- TA (Total Average)
- RC (Runs Created)
- RC/27 (Runs Rreated per game)
- wOBA (weighted On Base Average)
모델링 유형
- 비지도 학습: 군집(clustering)
PCA 주성분 분석
차원의 저주 (The curse of dimensionality)
다양한 Sabermetrics 지표들 :
머신러닝에서 데이터의 차원이 증가하면 차원의 수에 비해 학습데이터의 수가 줄어들면서 발생하는 문제를 의미함
데이터가 희박(sparse)해짐 탐색 할 공간이 늘어남 :
저장공간, 처리시간 문제 → 머신러닝 모델에 불필요한 부하 전체 공간에 비해 데이터 개수가 적으면 과대적합의 문제 우려
-> 데이터의 차원을 줄일 수 있는 방법 필요
Dimensionality Reduction (차원 축소)
데이터의 차원 = 독립변수의 수
차원 축소 : 변수(feature)의 개수를 줄임 (고차원의 데이터 → 저차원의 데이터)
다변량 변수 : 일반적으로 상관관계가 많음 = 불필요한 변수가 많을 수 있음 따라서, 서로 상관관계가 없는 변수(feature)들만 남기는 것이 목표
Feature Selection (변수 선택)
- 기존 feature 중에서 선택 (원래 변수를 유지)
- 종속변수와의 관계로 선택 여부 판단
- 상관관계가 없으면 feature 삭제
- 선택된 feature를 해석하기 쉬움
Feature Extraction (변수 추출)
- 새로운 feature 생성
- 기존 feature들로부터 새로운 feature 추출
- Feature 간 상관관계에 따라 차원 축소 용이
- 새롭게 생성된 feature의 해석 어려움
머신러닝 단계 중 데이터 이해 및 준비 단계에서 적용
차원이 줄어들면 원래 데이터가 가진 정보의 일부가 손실됨(information loss)
따라서, 차원 축소 시 원래의 feature들이 가진 분산의 특성을 유지하는 것이 중요함
주성분 분석 (PCA : Principal Component Analysis)
고차원 데이터를 효과적으로 분석하기 위한 대표적 분석 기법
독립변수들(features)의 분산을 가장 넓게 표현하는 주성분(새로운 축, PC)을 찾는 작업
주성분(PC)을 기존 feature(변수)의 수만큼 찾은 후 몇 개의 차원으로 축소할 지 결정함
PC1 : 첫번째 주성분- 가장 큰 분산
- 방향 : PC1의 eigenvector
- 길이 : PC1의 eigenvalue(PC1 축으로의 분산)
PC2 : 두번째 주성분 - 두번째로 큰 분산
- 방향 : PC2의 eigenvector
- 길이 : PC2의 eigenvalue(PC2 축으로의 분산)
Scree Plot을 사용하여 주성분(PC)의 개수를 정할 수 있음
주성분(PC)들의 eigenvalue를 그래프로 시각화 : 각 주성분들이 분산을 설명하는 비율에 대한 그래프
-> 일반적으로 엘보우 포인트까지의 주성분을 사용함
PCA 찾는 방법
1. 표준화: 각 feature들이 분석에 동등하게 기여할 수 있도록 표준화
2. 공분산 행렬 계산: Feature들이 함께 변하는 정도를 나타내는 공분산을 행렬 형태로 구성
3. 주성분(PC) 계산: 공분산 행렬의 eigenvector(고유벡터)들과 eigenvalue(고윳값)들 계산
4. Feature Vector 생성: 사용(선택)할 주성분(PC)들의 eigenvector들을 벡터 형태로 구성(행렬)
5. 데이터 조정: 주성분 축을 따라 데이터를 재조정
군집 알고리즘 이해
데이터 간의 유사도를 정의하고 그 유사도에 따라 군집을 형성하는 알고리즘
비지도 학습의 대표적인 예로서, 군집의 수, 속성 등이 사전에 알려져 있지 않을 때 주로 사용
유사도를 바탕으로 군집 내 응집도와 군집 간 분리도를 최대화하는 방식으로 군집을 구성함
데이터 간의 유사도는 거리의 개념으로 접근하는 것이 일반적임

군집화 종류
군집을 만드는 방법에 따라 분할적(partitional) 군집화, 계층적(hierarchical) 군집화 등으로 구분 분할적 군집화에도 중심, 밀도, 확률, 분포, 그래프 등에 기반한 다양한 방법 존재

계층적 군집 – H-Clustering
계층적 군집 방법 중 하나. 개체 간 거리에 따라 클러스터 계층을 표현하는 방식 비슷한 개체끼리 서로 묶어가며 클러스터를 만들어 가는 방법 (덴드로그램 이용)


- 선을 그어 가면 클러스터 수를 결정할 수 있음
- 데이터가 추가될 때의 계산이 맣음
분할적 군집 – K-means Clustering
K-means clustering : 가장 일반적으로 사용되는 분할적 군집 알고리즘
중심점(centroid)에 기반한 분할적 군집 알고리즘 : 거리의 평균을 적용
클러스터링의 개수(K)를 미리 정하고, 초기 중심점을 설정한 후 알고리즘에 따라 중심점 갱신을 반복함


2단계 -> 3단계 가까운 점에 해당하는 곳의 평균으로 중심점 이동: 이를 반복
K-means Clustering (시각화 site)
Visualizing K-Means Clustering
Visualizing K-Means Clustering
January 19, 2014 Suppose you plotted the screen width and height of all the devices accessing this website. You'd probably find that the points form three clumps: one clump with small dimensions, (smartphones), one with moderate dimensions, (tablets), and
www.naftaliharris.com
- 단점: K-means의 경우 기하학적인 모양에 약함
분할적 군집 – DBSCAN Clustering
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
- 밀도의 개념으로 군집을 형성 (높은 밀도)
- 군집 결과를 통해 noise 제거 가능 (낮은 밀도)
데이터 Point
- Core Point, Border Point : 군집을 이룸
- Noise Point : 이상치
하이퍼 파라미터
- epsilon(𝝐) : 이웃 반경
- minPts : 최소 샘플 수

1. 하나의 점 지정
𝜖 반경 내에 minPts(4개) 이상의 포인트 존재 → Core 1(파란색)
2. 반경 내에 점이 3개 뿐이므로 Core가 되지 못함, Core1의 군집에 포함된 점 -> Border
3. 1번과 마찬가지로 Core
4. 반경내의 점중에 Core가 표함되어 있으면 연결 -> 하나의 군집
분할적 군집 – DBSCAN Clustering (시각화 site)
Visualizing DBSCAN Clustering
Visualizing DBSCAN Clustering
January 24, 2015 A previous post covered clustering with the k-means algorithm. In this post, we consider a fundamentally different, density-based approach called DBSCAN. In contrast to k-means, which modeled clusters as sets of points near to their center
www.naftaliharris.com
분할적 군집 – K-means Clustering (초기화)
K-means 군집화는 초기 centroid의 위치에 따라 군집 결과가 달라질 수 있음
-> 초깃값에 따라 local optima에 빠질 수 있음
Ramdom seed :
가장 많이 사용되는 초기화 방법
임의로 초기화 점을 선택함
초깃값에 따라 좋지 않은 군집 결과 생성 가능
K-means++ :
초기 centroid들이 최대한 서로 멀리 떨어지도록 선택함
- 첫번째 centroid 랜덤 선택
- 나머지 centroid는 기존 centroid와 먼 점으로 선택
Random seed 초기화보다 빠르게 수렴
분할적 군집 – K-means Clustering (군집 수 결정)
K-means 알고리즘은 군집의 개수(K)를 정해야 함 → 적당한 수의 의미있는 군집을 표현하는 K 결정 필요
K-means의 군집화 결과를 판단하는 방법 : SSE, 실루엣 등
- 군집간 응집도가 높고 군집 간 분리도가 높으면 군집이 잘 만들어진 것
군집도 성능 평가
엘보우 기법: SSE, 오차제곱합
-> 군집 내 응집도만 봄
실루엣 기법
means 알고리즘은 군집의 개수(K)를 정해야 함 → 적당한 수의 의미있는 군집을 표현하는 K 결정 필요
-> 군집간의 분리도도 봄

실루엣 계수를 크기순으로 나열하여 시각화
군집 내 거리(내부 응집도):
- a(i): 데이터 포인트 i와 같은 군집 내 다른 데이터 포인트들과의 평균 거리.
- a(i) 값이 작을수록, i는 자신이 속한 군집에 더 잘 맞는다는 뜻
다른 군집과의 거리(외부 분리도):
- b(i): 데이터 포인트 i와 가장 가까운 다른 군집 내 데이터 포인트들과의 평균 거리.
- b(i) 값이 클수록, i는 다른 군집과 더 잘 분리되어 있다는 뜻

데이터 수집/이해
데이터 수집
수집 대상 데이터
참고 논문의 8가지 데이터로 분석 예정임 : OPS, ISO, SECA, TA, RC, RC/27, wOBA, XR
KBO 데이터 수집
KBO(한국야구위원회)에서는 과거 선수들의 기록에 대한 기초적인 데이터 제공 참고 논문과 같이 2000~2013년까지 규정타석 수를 채운 타자 594명의 데이터를 수집함
- 연도별 주요 선수들의 기록 제공
- 타자의 경우 규정타석 수를 채운 선수들의 기록을 제공
- csv file 등 데이터 다운로드 기능은 제공하지 않음
Web Scraping
Web scraping : 웹사이트에 표시되어 있는 내용을 가져와서 데이터를 분석하는 기법
KBO 데이터 수집 – 추가 데이터 소스 확인
추가 데이터 소스로 KBReport와 Statiz를 참고함
데이터 정리
Excel 수식을 사용하여 sabermetrics를 계산한 후 Azure Machine Learning Studio Designer에서 2000~2001년 데이터와 2002~2013년 데이터를 병합하여 분석하는 방식으로 실습 진행 예정
-> 형태가 다른 데이터를 병합해야
실습 데이터 업로드
Azure > Data > Create
> Data 3개 업로드
- 2000_2001_hitter
- 2002_2013_hitter
- 2014_hitter
아래의 column만 업로드

위의 목록 + YrPlayer
> Compute 생성
> Designer > Data > 업로드한 데이터 드래그앤 드롭
> 블록 더블클릭 > Ouputs > Data Output 옆의 아이콘 클릭 > Preview

데이터 준비
데이터 병합
Sabermetrics 계산 및 데이터 병합
Excel 수식을 사용하여 sabermetrics를 계산한 후 Azure Machine Learning Studio Designer에서 2000~2001년 데이터와 2002~2013년 데이터를 병합하여 분석하는 방식으로 실습 진행 예정
1. Designer > Add Rows Component를 추가하고 2000~2001년 데이터와 2002~2013년 데이터 연결
2. Add Rows Component를 추가하고 2014년 데이터 연결

수치 데이터 표준화
>Designer > Normalize Data Component를 사용하여 수치 데이터 표준화

> Normalize Data 블록 더블 클릭 > Edit column >Column types >Double

주성분 분석(PCA) - Python 코드 이용
Component로 제공되지 않는 기능/알고리즘의 사용을 위해 Python 코드 추가 가능
> Execute Python Script Component
> Node information에서 Comment 작성하여 기록

> Execute Python Script 더블클릭 > Edit code > Python 코드 추가

Save > Configure & Submit
중간 결과 확인 : 현재까지 작성 내용 실행
> Jobs > Execute Python Script 우측 마우스 클리 > Preview data > Result dataset

오늘의 간단한 후기
시간이 부족해서 인지 진행이 빨라서 따라가기가 쉽지 않았다. 또한 이론적인 내용이 많았는데, 수학적인 부분이 많아 이해가 쉽지 않았다. 그래도 여태까지 배웠던 것들에 대한 이해가 향상된 것 같아 좋았다. 실습을 따라가기 바빠서 하는 동안 현재 무엇을 하고 있는 지에 대한 감을 잡기가 쉽지 않아서 그 점에 유의해야 할 것 같다. 그리고 데이터 수집 및 전처리가 쉽지 않은데 많은 부분이 되어 있어서 새삼 감사함을 느꼈다
출처
[1] Tistory, "마이크로서비스 아키텍처(Microservice Architecture) 이해하기," *Be Curious Blog*. [Online]. Available: https://bcho.tistory.com/m/1206?pidx=12. [Accessed: Jan. 17, 2025].
[2] 네이버 블로그, "AI란 무엇인가요? 인공지능의 모든 것," *네이버 블로그*. [Online]. Available: https://m.blog.naver.com/with_msip/221808512417. [Accessed: Jan. 17, 2025].
[3] MQL5, "머신러닝을 사용하여 트레이딩 알고리즘 작성하기," *MQL5 Articles*. [Online]. Available: https://www.mql5.com/ko/articles/11200. [Accessed: Jan. 17, 2025].
[4] Tistory, "머신러닝을 활용한 고객 이탈 예측," *Snowwhite1106 Blog*. [Online]. Available: https://snowwhite1106.tistory.com/152. [Accessed: Jan. 17, 2025].
[5] Stack Overflow, "Small learning rate vs. big learning rate," *Stack Overflow*. [Online]. Available: https://stackoverflow.com/questions/62690725/small-learning-rate-vs-big-learning-rate. [Accessed: Jan. 17, 2025].
[6] Naver Blog, "Gradient Descent의 이해와 활용," *pmw9440 Blog*. [Online]. Available: https://m.blog.naver.com/pmw9440/221822183325. [Accessed: Jan. 17, 2025].
[7] H. Wony, "회귀분석의 기초와 이해," *Hiwony7933 GitHub Blog*. [Online]. Available: https://hiwony7933.github.io/document/3.%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D/2.%ED%9A%8C%EA%B7%80%EB%B6%84%EC%84%9D/1.%ED%9A%8C%EA%B7%80%EB%B6%84%EC%84%9D.html. [Accessed: Jan. 17, 2025].
[8] Da-ta Online, "복제 4-3: 분류분석," *Da-ta Online*. [Online]. Available: https://www.da-ta.online/%EB%B3%B5%EC%A0%9C-4-3-%EB%B6%84%EB%A5%98%EB%B6%84%EC%84%9D. [Accessed: Jan. 17, 2025].
[9] Data Newbie, "머신러닝 기초: 분류와 회귀," *Data Newbie Blog*. [Online]. Available: https://data-newbie.tistory.com/25. [Accessed: Jan. 17, 2025].
[10] BskyVision, "가장 간단한 군집 알고리즘: k-means 클러스터링," *BskyVision Blog*. [Online]. Available: https://bskyvision.com/entry/%EA%B0%80%EC%9E%A5-%EA%B0%84%EB%8B%A8%ED%95%9C-%EA%B5%B0%EC%A7%91-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-k-means-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%A7%81#google_vignette. [Accessed: Jan. 17, 2025].
[11] N. Harris, "Visualizing K-Means Clustering," *Naftali Harris Blog*. [Online]. Available: https://www.naftaliharris.com/blog/visualizing-k-means-clustering/. [Accessed: Jan. 17, 2025].
[12] YG Analyst, "ML Clustering," *YG Analyst Blog*. [Online]. Available: https://yganalyst.github.io/ml/ML_clustering/. [Accessed: Jan. 17, 2025].
[13] N. Harris, "Visualizing DBSCAN Clustering," *Naftali Harris Blog*. [Online]. Available: https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/. [Accessed: Jan. 17, 2025].
[14] Hyunseo, "DBSCAN 클러스터링 알고리즘: 밀도 기반 클러스터링," *Hyunseo's Blog*. [Online]. Available: https://hyunse0.tistory.com/49. [Accessed: Jan. 17, 2025].
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(강명호 강사님)을 기반으로 제작되었습니다
깃허브 소스코드의 내용을 담고 있습니다
Microsoft에서 제공하는 Dataset을 포함하고 있습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다