
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- MS
- 마이크로소프트 ai 스쿨
- 마이크로소프트 AI
- 마이크로소프트 ai school 6기
- 마이크로소프트 ai 스클
- microsoft ai school
- micsrosoft ai
- microsoft ai
- microsoft ai school 6기
- microsoft
- 마이크로소프트
- msai
- 마이크로소프트 ai 스쿨 6기
- Today
- Total
연랩
Data Augmentation(데이터 증강) 본문
프로젝트 배경
- 독일 교환학생 DLML und KI (Deep Learning Machine Learning and AI) 수업에서 프로젝트로 수행
- 수강생들에게 Data Augmentation에 대해 설명하는 강의 형식으로의 발표 진행
- 데이터 증강의 효용성을 설명하기 위해 작은 neural network를 데이터 증강이 없는 상태로 한 번, 있는 상태로 한번 훈련 시켜 비교
- 서로 다른 국적의 3명이서 팀프로젝트를 운영
(중간에 한 명이 사라지긴 했지만.....)
주요 역할과 경험
- Data augmentation for Images, texts, time series 중 Images 부분을 담당하여 진행
- TensorFlow tutorial과 Fashion-MNIST 데이터 셋을 이용하여 이미지 분류 수행
- 데이터 셋의 이미지 수를 줄여 정확도를 본 후, 줄인 데이터 셋을 증강하여 분류한 것과의 결과 비교
- Google Colab 과 Tensorflow 를 이용하여 Data Augmentation 시각화
프로젝트 내용
데이터 증강이란?
: 학습 데이터를 늘리는 것
neural network의 성능으로 높이고 오버피팅을 극복할 수 있는 방법은 데이터의 양을 늘리는 것이다
따라서 이를 위해 이미지의 경우로 예를 들면, 이미지를 회전하거나 뒤집거나 색을 바꾸는 등의 행위를 해 데이터의 양을 늘리는 것이다.
예를 들어,

이 튤립 사진을 뒤집거나 색 반전, 확대를 하는 등의 절차를 이용하여 사진의 양을 늘려 학습 데이터를 늘리는 것이다.


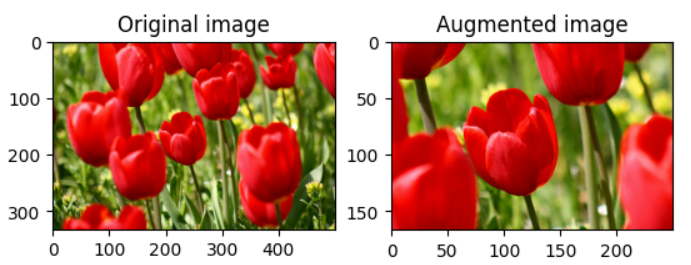
이렇게 단순히 몇 개의 예시만 가져와도 하나의 튤립사진이 4개로 늘어났음을 알 수 있다. 이처럼, 데이터를 인위적으로 늘려, 데이터 셋의 양을 늘리는 것을 Data Augmentation, 즉, 데이터 증강이라고 부른다.
자세한 내용과 이와 관련한 코드는 아래 "Tensorflow | Data Augmentation"링크를 참조하기를 바란다.
(앞선 사진들의 출처도 여기이다)
https://www.tensorflow.org/tutorials/images/data_augmentation?hl=ko
데이터 분류(Data Classification)
데이터 분류란 말 그대로 데이터를 알맞은 곳이 분류하는 것이다. 예를 들어 티셔츠를 티셔츠로 분류하고, 바지를 바지로 분류할 수 있는 모델을 말한다.

이러한 Fashion 데이터를

이러한 카테고리로 분류하는 것이다.
자세한 내용과 이와 관련한 코드는 아래 "Basic classification: Classify images of clothing"링크를 참조하기를 바란다.
(앞선 사진들의 출처도 여기이다)
https://www.tensorflow.org/tutorials/keras/classification?hl=ko
데이터 증강의 효용성
나는 이 데이터 분류를 활용하여 데이터 증강의 효용성을 해당 프로젝트에서 보이고자 하였다.
즉, "원래 전체 데이터를 분류 했을 때의 정확도", "전체 데이터의 양을 줄여서 분류했을 때의 정확도", "줄인 데이터를 증강 했을 때의 정확도"를 비교하여 데이터 증강의 효용성을 시각화 하고자 하였다.

사용한 데이터 셋은 앞선 언급했던 Fashion MNIST이다.
먼저, Tensorflow의 Fashion MNIST 전체 데이터를 사용하여 80%의 자료는 훈련용(training) 20%의 자료는 validation용으로 활용하였을 때의 결과는 다음과 같았다.
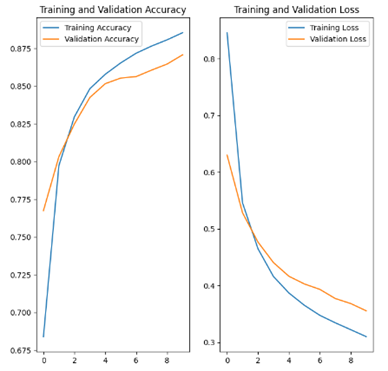
데이터 증강은 Keras preproducing layer를 사용하여 진행하였다.


RandomFlip와 RandomRotation을 주로 사용하였는데 그 이유는 나중에 설명하도록 하겠다.
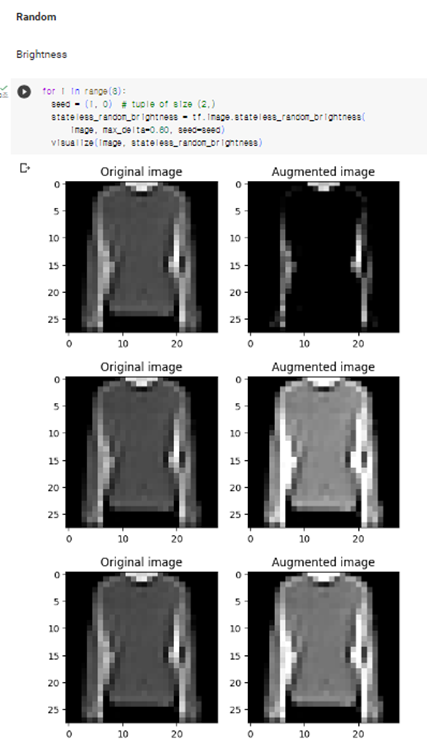
Fashion MNIST 데이터를 증강하면 다음과 같았다.


이러한 augment 방식을 Random으로 지정하여 데이터를 늘릴 수 있었다.
이와 같은 방식으로 데이터 증강을 하였는데, 데이터 증강의 효용성을 보기 위해 데이터를 줄인 양별로 비교하여 데이터 증강의 효과를 보면 다음과 같다.
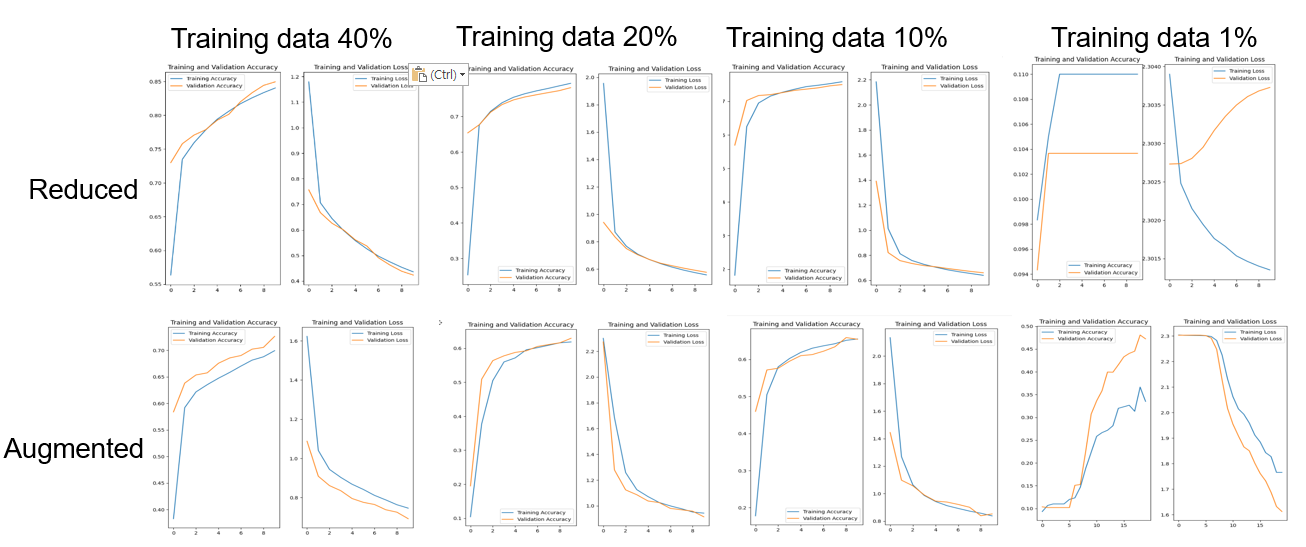
그리고 epoch를 늘리면 조금 더 면밀하게 데이터 증강에 효과가 있음을 알 수 있다
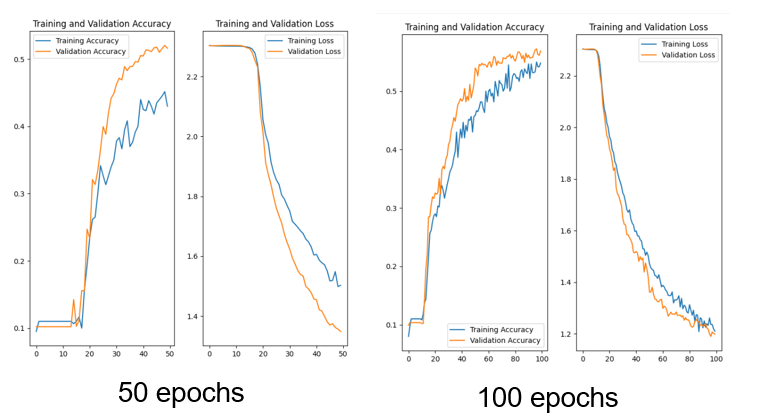
이외...
이와 같은 내용을 강의 형식으로 발표하는 프로젝트였다. 따라서 코드를 시범으로 앞에서 보이고, 또한 빈칸을 뚫어 다같이 참여할 수 있는 형식으로 발표를 진행하였다. 또한, 후에 paper를 제출하는 것까지가 마무리였다. 제출하였던 Paper는 다음과 같았다.

Abstract부터 출처까지 형식이 갖추어진 제출물이었지만, 다른 팀원들과 함께 만든 것이므로 블로그에 파일로 전체 공개하는 것은 힘들 것 같다.
다만, 연락주시는 분들의 경우, 따로 연락을 취하고 공개하겠습니다
프로젝트를 하면서 어려웠던 점
일단, 생각보다 데이터 증강의 조건이 까다롭다는 사실을 알게 되었다.
데이터 증강의 예시로 있었던 꽃 사진의 경우, 사진을 자르거나, gray scale로 바꾸는 등 다양한 방식을 취할 수 있어 동일하게 적용하면 될 것이라 생각하였지만, Fashion MNIST 데이터 셋의 경우 그렇지 못했다.
예를 들어, 튤립 사진을 자르면 이렇게 되어 여전히 튤립임을 알아볼 수 있지만,
티셔츠 사진의 경우,

이런 형태가 되어 티셔츠인지 알아볼 수 없는 데이터가 생성되어 오류가 생겼다.
그 밖에도, 이미 grayscale 이미지여서 grayscale로의 전환이나 채도 조절이 불가능하였다.
즉, 데이터의 종류에 따라 취할 수 있는 Augment 방식이 다르다는 것을 알게 되었다.
또한, 아직까지 분류의 정확도가 낮아서 그런 것인지 모르겠으나, 생각보다 데이터 증강의 효과를 보기가 힘들었다. 일정 수준 이상의 양의 데이터로 하면 증강 유무에 따른 차이가 나지 않았으며, 데이터 양이 너무 적으면, 증강의 유무와 상관 없이 그래프가 전혀 다르게 나왔다.
그리고 할 때마다 그래프의 모양이 다르게 나왔는데, 증강된 데이터의 질이 좋으면 학습이 잘 이루어져 원하는 대로 결과가 나오지만, 그렇지 않은 경우 실패하는 일이 종종 있었다.
epoch 수를 늘리면 이러한 단점을 해결할 수 있었지만, 시간이 너무 오래걸린다는 단점이 있었다.
그 밖에...
사실 내가 수행한 부분이 'image' 였을 뿐, times series에 관한 부분도 팀원이 수행해 주어 잘 발표를 마쳤다.
간단히 살펴 보면 다음과 같다.


같이 프로젝트 하면서 알게 된 사실인데, 독일 친구들은 출처에 굉장히 민감하다. 그래서 같이 발표자료 만들고, paper 만들면서 citavi라고 하는 출처 적는 데 도움이 되는 새로운 툴을 알게 되었다. 조금쯤은 간과하고 있었던 것을 깨닫게 된 좋은 계기였다고 생각한다.
간단한 후기
머신러닝과 인공지능 수업을 들은 것도, 프로젝트를 수행해 본 것도 처음이어서 쉽지 않았지만 재미도 있고 값진 경험이었다. 또한, 영어로 발표하고 과제를 수행한 것도 뜻 깊은 경험이었다. 새로운 것들이 투성이인 프로젝트 였지만, 좋은 경험이었다고 생각한다.
출처
[1] C. Sun, A. Shrivastava, S. Singh, and A. Gupta, “Revisiting Unreasonable Effectiveness of Data in Deep Learning Era,” International Conference on Computer Vision, pp. 843–852, 2017, doi: 10.1109/ICCV.2017.97.
[2] B. K. Iwana and S. Uchida, “An empirical survey of data augmentation for time series classification with neural networks,” PloS one, vol. 16, no. 7, 2021, doi: 10.1371/journal.pone.0254841.
[3] TensorFlow Datasets. "Fashion MNIST." TensorFlow Datasets Catalog. [Online]. Available: https://www.tensorflow.org/datasets/catalog/fashion_mnist?hl=en. [Accessed: June 16, 2023].
[4] TensorFlow. "Keras: Basic classification." TensorFlow Tutorials. [Online]. Available: https://www.tensorflow.org/tutorials/keras/classification?hl=ko. [Accessed: June 18, 2023].
[5] "TensorFlow: Data augmentation" [Online]. Available: https://www.tensorflow.org/tutorials/images/data_augmentation?hl=ko#%EB%AA%A8%EB%8D%B8_%ED%9B%88%EB%A0%A8%ED%95%98%EA%B8%B0. [Accessed: June 18, 2023].
[6] Gholamy, A., Kreinovich, V., & Kosheleva, O. (2018). Why 70/30 or 80/20 relation between training and testing sets: A pedagogical explanation.
[7]TH Koeln DLML and KI (Dr. Daniel Gaida and Dr. Wolgang Konen) learning materials and learning contents, project results for the 2023 summer semester
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용은 2023 여름학기 TH Koeln DLML und KI(Course by Prof. Dr.Daniel Gaida and Prof. Dr. Wolfgang Konen)학습자료 및 학습 내용을 담고 있습니다.
This post includes TH Koeln DLML and KI (Dr. Daniel Gaida and Dr. Wolgang Konen) learning materials and learning contents for the 2023 summer semester
'프로젝트' 카테고리의 다른 글
| Azure Open AI를 활용한 독립 운동 관련 공익성 웹서비스 : 독립해결사 (0) | 2025.04.18 |
|---|---|
| 머신러닝과 커스텀비전을 활용한 퍼스널컬러 기반 중고 거래 플랫폼(모바일 앱) : Personal (0) | 2025.02.26 |
| 데이터 분석: 날씨(기온, 습도)와 스포츠 관중 수와의 관계 (3) | 2024.11.28 |
| AI 번역 기능을 탑재한 예약 관리형 챗봇(ChatBot): Space Chat (5) | 2024.11.01 |
| AWS cloud를 이용한 데이터 마이그레이션(Data Migration) (8) | 2024.10.14 |



