

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 마이크로소프트 ai 스클
- 마이크로소프트 ai 스쿨
- 마이크로소프트 ai school 6기
- microsoft ai
- microsoft ai school 6기
- microsoft ai school
- msai
- 마이크로소프트 ai 스쿨 6기
- 마이크로소프트
- MS
- 마이크로소프트 AI
- micsrosoft ai
- microsoft
- Today
- Total
연랩
[Microsoft AI School 6기] 1/13(18일차) 정리 - 생성 AI, Stable diffusion(SDXL) 본문
[Microsoft AI School 6기] 1/13(18일차) 정리 - 생성 AI, Stable diffusion(SDXL)
parkjiyon7 2025. 1. 13. 18:04생성 AI(Generative AI)
복습
생성 AI (Generation AI)
이미지, 텍스트, 음악, 비디오 등 새로운 콘텐츠를 만들어 내는 AI 모델과 알고리즘을 연구하는 분야를 의미함
TTS(Text-to-Speech)
UniAudio: Towards Universal Audio Generation with Large Language Models | UniAudio_demo

Prompt
TTS 모델에 입력으로 주어진 샘플 또는 음성
용도:모델이 특정 스타일, 억양, 목소리를 학습하도록 참고로 제공되는 데이터
- "Zero-shot TTS"라는 맥락에서는 모델이 훈련되지 않은 새로운 스타일이나 화자의 목소리를 이 프롬프트를 기반으로 모방하려고 시도
Generated Speech
TTS 모델이 생성한 결과 음성입니다.
용도:모델이 텍스트를 기반으로 생성한 합성 음성
- "Prompt"에서 제공된 목소리 스타일이나 억양을 따라하려고 시도한 결과
Text-to-Music
MusicGen
AudioCraft
AudioCraft is a single-stop code base for all your generative audio needs: music, sound effects, and compression after training on raw audio signals.
audiocraft.metademolab.com
에이전트
일반 에이전트
- 2025 기대되는 AI 기술 중 하나
Claude -2가 각광받고 있음
작업특화 에이전트
수학 문제 해결이나 학문적 연구 증의 환경에서 동작하는 에이전트에 대한 벤치마크도 나타나고 있다
이미지 생성 AI

가상머신 생성 후 WebUI 설치, 그 위에 다양한 모델들을 설치
생성 AI
Text Generation
AI 모델을 이용하여 입력 프롬프트를 기반으로 인간이 작성한 것 같은 텍스트를 생성하는 것
- Chat GPT와 같은 GPT에서는 Transformer architecture 사용
- 비디오 생성은 시간 요소가 포함되기 대문에 이미지 생성보다 복잡
Image Generation
대표적인 생성기술인 GAN(Generative Adversarial Networks)은 이미지는 만드는 생성자와 진위여부를 판단하는 구별자로 구성
- 이 두 시스템이 피드백 루프에서 서로 경쟁하면서 생성자는 구별자가 진위여부를 반별할 수 없을 대까지 학습하며 더 좋은 이미지를 생성
Audio Generation
- 음성 소리 분야에도 GAN 기술이 적용됨(WaveGAN)
- Tacotron 2와 같은 TTS는 엑스트를 입력 받아 음성 생성
- 대량의 데이터셋을 학습하여 소리 뉘앙스를 습득
Image 생성 AI
생성 모델은 데이터의 분포를 학습하여 새로운 데이터 생성
기존의 분류 모델은 데이터를 학습한 후 분류를 위한 결정 경계를 찾음
GAN
생성자(Generator)와 판별자(Discriminator)가 경쟁하는 방식으로 학습하는 딥러닝 모델
생성 모델: 데이터를 생성할 수 있는 확률 분포를 학습하는 모델
Discriminative 모델: 주어진 데이터의 분류에 초점.

생성된 가짜 이미지가 원래 데이터의 분포를 따름
-> 잘 학습된 모델은 통계적으로 평균적 특징을 포함하는 이미지 데이터 생성이 용
VAE
생성모델: 잠재 공간에서 샘플링하여 새로운 데이터를 생성하거나 변형하는 모
- VAE(Variational Autoencoder)는 데이터를 압축하고 다시 복원하는 모델
- VAE는 단순히 데이터를 압축하는 것이 아니라, 데이터의 숨겨진 구조를 학습하고 이를 바탕으로 새로운 데이터를 만들 수 있는 모델
-> VAE는 입력 데이터를 압축해서 중요한 특징만 추출하고, 이를 바탕으로 새로운 데이터를 생성
인코더: 데이터를 요약해서 중요한 정보만 뽑아냅니다.
디코더: 그 요약된 정보를 가지고 원래 데이터를 복원하거나 새로운 데이터를 생성합니다.
확산 모델(Diffusion Probabilistic Model)
확산 모델은 학습 데이터에 지속적으로 잡음(noise)를 추가하여 손상 -> 잡음을 제거해 가며 원상 복구하는 방식의 생성 모델

- 이미지의 픽셀들이 시간의 흐름에 따라 변하도록 노이즈 추가

- 잡음 이미지로부터 시간의 흐름에 따라 denoising 하여 이미지 생성
ex) Stable diffusion, DALLE-2
Transformer 모델
Transformer 모델의 역할은 주로 시퀀스 데이터를 처리하고 이해하거나 생성
문장, 텍스트, 시간 순서가 있는 데이터에서 중요한 관계를 파악하고, 그 데이터를 기반으로 여러 작업을 수행하는 데 사용
Stable Diffusion
- Diffusion 모델의 가장 대표적인 서비스
독일 뮌휀 대학교 연구실에서 Latent text-to-image 모델을 기반으로 개발된 생성형 인공지능 모델
- 비교적 가벼운 모델로 컴퓨팅 리소스가 많이 필요하지 않아 PC 환경에서도 동작이 가능
- 오픈 소스로 공개하여 사용자 수가 많으며 지속적으로 늘어나고 있음
- 다양한 플러그인을 활용하여 확장이 가능함
Open Source License
오픈소스 라이선스는 소프트웨어 사용, 수정 및 배포와 관련된 계약의 일정으로 free software movement와 함게 확산되어 현재 IT industry에서는 빼놓을 수 없는 트랜드로 자리잡음
참고) stable diffuaion은 mit라이선스라고 함
AI 모델
AI 기술의 발전으로 관련 저작물이 많이 나오면서, 소스코드 이외에도 AI 학습데이터나 AI모델에 대해 제한하는 표준 라이선스들이 사용되고 있음
- CreativeML Open RAIL-M: Stability AI에서 만든 오픈소스 머신러닝 전용 라이선스
Stable diffusion 기본구조
CLIP: 입력된 텍스트를 인코딩하여 Token 형태로 변환 후 UNet에 전달
UNet: 전달된 Token으로 무작위 생성된 noise을 denoising(반복-> 제대로된 이미지 생성)
VAE: 이미지를 픽셀로 반환

Stable Diffusion base models
모델(model, check point) 파일은 일바나적인 이미지 혹은 특정한 장르의 이미지를 생성하기 위한 모적으로 미리 학습된 stable diffusion 가중치를 의미.
Stable Diffusion Model- fine tuned models
미세 조정 모델9fine tuned model은 특정 분야 이미지 생성에 특화된 모델을 의미
가중치(filter,kernel) 재학습 또는 추가 학습: fine-tuned
ex) 지브리 스타일 그림
ComfyUI
최근에 사용이 늘고 있는 UI 중 하나로 워크플로우 기반으로 이미지 생성
사용자 인터페이스가 Web UI나 Easy Diffusion과는 상당히 다르게 구성되어 처음 사용 시 어려울 수 있음
- 가볍고 속도가 바름
- 설정의 자유도가 높음
- 데이터의 흐름 파악 용이
- 생성된 파일에 워크플로우 전체가 들어 있어서 공유가 용이
Image tools
Outpainting
이미지를 특정 방향으로 확장할 때 사용하는 기능
(배경 확장)
Upscaling
stable siffusion의 기본 생성 이미지는 이미지의 크기가 작기 때문에 AI 기술을 이용하면 좋은 품질의 이미지를 얻을 수 있음
Inpainting
생성된 이미지에서 마음에 안드는 부분이 있을 때, inpainting 기능을 이용하여 다시 그릴 수 있음
ControlNet
구도 및 피사체의 자세를 복제할 수 있는 신경망
Stable diffusion으로 생성되는 이미지에서 피사체의 위치, 모습 등을 제어 가능
- 텍스트에서 이미지를 생성하는 Diffusion 모델에 조건적 제어를 추가하는 프레임워크
- 특히 Stable Diffusion과 같은 모델에 공간적 맥락을 추가하여, 모델이 특정 조건에 맞는 이미지를 더 정확하게 생성
실습
1) Base model 설치
xl model 다운로드
sd_xl_base_1.0.safetensors · stabilityai/stable-diffusion-xl-base-1.0 at main
sd_xl_base_1.0.safetensors · stabilityai/stable-diffusion-xl-base-1.0 at main
Git LFS Details SHA256: 31e35c80fc4829d14f90153f4c74cd59c90b779f6afe05a74cd6120b893f7e5b Pointer size: 135 Bytes Size of remote file: 6.94 GB Git Large File Storage (LFS) replaces large files with text pointers inside Git, while storing the file contents o
huggingface.co
> sd_xl_base_1.0.safetensors> copy download link
경로
~/stable-diffusion-webui-forge/models/Stable-diffusion
curl -H "Authorization: Bearer <your key here>" https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors --location --output sd_xl-base_1.0safetensors
2) refiner 모델 설치
Refiner 모델은 주로 이미지 생성 또는 개선 작업에서 사용되는 후처리 모델로, 처음 생성된 이미지를 더 나은 품질로 개선하거나 세부사항을 추가하는 데 사용
refiner 모델
번호: 84040
SDXL Unstable Diffusers ☛ YamerMIX - NihilMania | Stable Diffusion XL Checkpoint | Civitai
SDXL Unstable Diffusers ☛ YamerMIX - NihilMania | Stable Diffusion XL Checkpoint | Civitai
For business inquires, commercial licensing and consultation contact me under yamer@rundiffusion.com , for custom LoRAs visit my ko-fi page ! Follo...
civitai.com
~/stable-diffusion-webui-forge/models/Stable-diffusion
civitdl 84040 . -k <your civitai key>
3) WebUI 실행
~/stable-diffusion-webui-forge
./webui.sh --share --enable-insecure-extension-access --gradio-auth <ID>:<Password>
SD1.5 test

위와 같은 프롬포트를 작성하면 아래와 같은 사진이 나온다

Batch count는 묶음처리를 얼만큼 할 것인가(횟수): 주머니 개수
Batch size는 묶음 크기(한번에 처리하는 크기): 주머니 안 사탕 수
Batch count 4, Batch size 1이면 아래와 같이 나온다

Batch count 1, Batch size 4이면 아래와 같이 나온다

SDXL test
- xl은 1024*1024로 학습하였기 때문에 이미지 사이즈를 이와 유사하게 설정해주어야 결과가 잘 나온다
- Genteration에서 Euler a/ karras로 변경하여도 잘됨
CFG 5-7 권

Batch size 2, Batch count 2, 1024*1024로 생성하면 다음과 같다

Euler a로 생성

Prompt
prompt guide
Stable Diffusion prompt: a definitive guide - Stable Diffusion Art
Stable Diffusion prompt: a definitive guide - Stable Diffusion Art
Developing a process to build good prompts is the first step every Stable Diffusion user tackles. This article summarizes the process and techniques developed
stable-diffusion-art.com
seed: -1 랜덤 시드라는 뜻이다
prompt 앞에 나올수록 가중치가 높음
ex)
A sorceress -> 마법사 한명만 나옴

Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing

Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting

Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body

화풍 또한 추가할 수 있다
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha

Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation

Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly beautiful, dystopian, iridescent gold

프롬프트가 좋아질수록 이미지의 퀄리티가 좋아짐을 알 수 있다
부정 프롬프트/긍정 프롬포트
portrait photo of a man

-> 콧수염을 제거할 예정
긍정 프롬포트만 사용
portrait photo of a man without mustache

오히려 콧수염이 강조됨을 알 수 있다
부정 프롬프트 사용
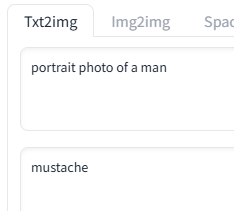

부정프롬프트를 사용하면 해당하는 사람들이 제외됨을 알 수 있다
텍스트(프롬프트) 작성 방법
프롬프트는 명료하고 자세하게 작성하는 것이 유리함
- 주제/중심 피사체
- 소재/작화 기법
- 화풍/스차일
- 구도
- 생상&조명
- 해상도
- 예술, 작가 실명
(())를 사용하면 강조 가능
프롬프트에는 생성하고자 하는 이미지에 대한 자세한 정보를,
부정 프롬프트에서는 생성하고자 하는 이미지에서 '원하지 않는' 내용을 기술
- 문장이 아닌 키워드로
- 중요한 키워드를 앞에
- 괄호는 모든 것에 우선
- 키워드 블렌딩(프롬프트 스케줄링)
- 가중치 직접 지정(아름다움:1.5)
- 다른 작품의 프롬프트 적용
Refiner
img2img
refiner을 이용하여 정제할 수 있도록 분리해놓았다
1) 프롬프트로 이미지 생성

2) refiner
seed 저장 > 사진 아이콘 클릭


refiner 체크
switch 0.8 ->20%남았을 때부터 refiner가 작동


이미지가 보다 사실적으로 구성되었음을 알 수 있다. 옷감이나 배경을 살펴보면 이미지의 품질이 증가하였음을 알 수 있다
switch 0.2

헤드폰이 이상하지만 조금 더 사실적으로 표현되었음을 알 수 있다
Denoising Strength
- 얼마나 노이즈를 강하게 제거할 지를 결정
- 앞서 생성한 엠마왓슨 이미지를 이용하여 디노이징을 수행



denoising 숫자가 올라갈 수록 자유도가 높아져 그림이 창의성이 높아짐을 볼 수 있다
Sketch
Img2img 탭 내에 있는 Sketch 기능을 사용하여 손으로 그린 스케치를 이미지로 변환 가능


밑그림을 잘 그린 후 생성하면 보다 완성도 높은 이미지를 얻을 수 있다
Outpainting
이미지를 특정 방향으로 확장할 떄 사용하는 기능
이미지의 양옆, 위아래를 이미지와 유사한 느낌으로 확장하고 싶을 떄 주로 사
img2img


(해당 결과는 조금 실망스러움을 알 수 있다...ㅠ)
Upscale
이미지 아래 삼각자 or Extras
윤곽이 선명하고 이미지 자체가 선명해짐을 알 수 있다


이미지의 화질이 마음에 들지 않으면 업그레이드 할 수 있다
Inpainting
txt2img 이미지 아래의 팔레트 아이콘 or img2img > Inpaint

Inpaint를 통해 일부 변경 가능
ex) Emma Watson > Margot Robbie
배경제거
extensions>available

intsalled 가서 apply and restart UI 클릭

powershell에서 다시 실행
Extras > Remove background
Upscale 해제

u2net으로 설정 변경



이미지의 배경이 제거되었음을 알 수 있다
손가락 실습
손가락과 피아노 건반 등 반복적인 그림을 잘 못 그리는 AI를 실험하기 위해 다음과 같이 구상하였다

생성한 이미지는 다음과 같다

LoRA
Low-Rank Adaptation으로 stable diffusion을 미세 조정하는 방법 중 하나
체크포인트에 비해 크기가 작기 때문에 여러 실험을 해보기에 적합
-> 피아노 이미지로 진행
civitai > filter

수채화 LoRA
https://civitai.com/models/484723/watercolor-style-sdxl

아까 생성한 피아노 이미지들을 seed로 하여 수채화 LoRA를 적용 시켜 이미지를 생성하면 다음과 같다

반고흐 LoRA
https://civitai.com/models/650132?modelVersionId=750855
아까 생성한 피아노 이미지들을 seed로 하여 Vincent Van Gogh LoRA를 적용 시켜 이미지를 생성하면 다음과 같다

Tip: UI내에서 LoRA 새로 고침 가능

Wrong LoRA
부정프롬프트에 들어갈만한 것들로만으로 구성. 즉, 부정프롬포트에 들어갈 만한 것들을 다 넣으면 원치 않는 것은 생성되지 않는다는 것에서 기원
아래 링크에서 다운로드 가능
https://huggingface.co/minimaxir/sdxl-wrong-lora

부정 프롬포트에 wrong 추가
seed는 피아노 이미지와 동일

ControlNet
피사체의 자세를 복제할 수 있는 신경망
stable diffusion으로 생성되는 이미지에서 피사체의 위치, 모습 등을 제어 가능
1) sd-webui-controlne 다운로드
Extensions > Install from URL
https://github.com/Mikubill/sd-webui-controlnet
GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
WebUI extension for ControlNet. Contribute to Mikubill/sd-webui-controlnet development by creating an account on GitHub.
github.com
URL for extension's git repository에 입력
Installed > sd-webui-controlnet 확인
2) 파일 다운로드
Hugging Face에서 아래 링크 접속
https://huggingface.co/lllyasviel/sd_control_collection
sd_control_collection/thibaud_xl_openpose.safetensor > copy downloadlink
~/stable-diffusion-webui-forge/models/ControlNet
wget https://huggingface.co/lllyasviel/sd_control_collection/resolve/main/thibaud_xl_openpose.safetensors

아래의 총알문양을 누르면 우측 그림이 나온다

기타 설정들과 프롬프트를 완성해주고 genertate을 누른다

위와 같이 해당 자세의 이미지가 나옴을 알 수 있다
오늘의 간단한 후기
다양한 모델들과 방법을 활용하여 여러 이미지를 생성해보는 경험을 하는 것이 즐거웠다. 시간이 조금 모자라서 마지막에 서둘러서 아쉬웠지만, 설명도 차분히 잘 해주시고 실습도 재미있어서 오늘의 결과물이 뿌듯했다. AI를 통해 다양한 방법으로 이미지를 생성할 수 있다는 것이 신기해다
출처
[1] UniAudio, "UniAudio: Towards Universal Audio Generation with Large Language Models | UniAudio_demo," *UniAudio*. [Online]. Available: https://uniaudio_demo. [Accessed: Jan. 13, 2025].
[2] Meta, "MusicGen: AI-Based Music Generation," *AudioCraft*. [Online]. Available: https://audiocraft.metademolab.com/musicgen.html. [Accessed: Jan. 13, 2025].
[3] Kobiso, "Research AI Terms," *Kobiso Research*. [Online]. Available: https://kobiso.github.io/research/research-ai-terms/. [Accessed: Jan. 13, 2025].
[4] AssemblyAI, "Diffusion Models for Machine Learning: Introduction," *AssemblyAI Blog*. [Online]. Available: https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/. [Accessed: Jan. 13, 2025].
[5] O. Mishra, "Stable Diffusion Explained," *Medium*. [Online]. Available: https://medium.com/@onkarmishra/stable-diffusion-explained-1f101284484d. [Accessed: Jan. 13, 2025].
[6] Civitai, "SDXL Unstable Diffusers - Yamermix," *Civitai*. [Online]. Available: https://civitai.com/models/84040/sdxl-unstable-diffusers-yamermix. [Accessed: Jan. 13, 2025].
[7] Stable Diffusion Art, "Stable Diffusion Prompt Guide," *Stable Diffusion Art*. [Online]. Available: https://stable-diffusion-art.com/prompt-guide/. [Accessed: Jan. 13, 2025].
[8] Civitai, "Watercolor Style SDXL," *Civitai*. [Online]. Available: https://civitai.com/models/484723/watercolor-style-sdxl. [Accessed: Jan. 13, 2025].
[9] Civitai, "Model Version 750855," *Civitai*. [Online]. Available: https://civitai.com/models/650132?modelVersionId=750855. [Accessed: Jan. 13, 2025].
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(강명호 강사님)을 기반으로 제작되었습니다
깃허브 소스코드의 내용을 담고 있습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다
'MS AI school 6기' 카테고리의 다른 글
| [Microsoft AI School 6기] 1/15(20일차) 정리 - AI 기본의 이해 및 활용, 인공지능 윤리 (0) | 2025.01.15 |
|---|---|
| [Microsoft AI School 6기] 1/14(19일차) 정리 - 생성AI, Stable Diffusion, Flux, AI 동영상 제작 (0) | 2025.01.14 |
| [Microsoft AI School 6기] 1/10(17일차) 정리 - 클라우드 컴퓨팅(5) (2) | 2025.01.10 |
| [Microsoft AI School 6기] 1/9(16일차) 정리 - 클라우드 컴퓨팅(4) (1) | 2025.01.09 |
| [Microsoft AI School 6기] 1/8(15일차) 정리 - 클라우드 컴퓨팅(3) (1) | 2025.01.08 |



