

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 마이크로소프트 ai 스쿨
- 마이크로소프트 ai 스쿨 6기
- msai
- microsoft ai school 6기
- microsoft
- MS
- 마이크로소프트 ai school 6기
- 마이크로소프트 ai 스클
- 마이크로소프트
- microsoft ai school
- 마이크로소프트 AI
- micsrosoft ai
- microsoft ai
- Today
- Total
연랩
[Microsoft AI School 6기] 12/27(8일차) 정리 - NumPy, Pandas 본문
[Microsoft AI School 6기] 12/27(8일차) 정리 - NumPy, Pandas
parkjiyon7 2024. 12. 27. 17:55파이썬 기본 문법
조건부 표현식(conditional expression)
변수 = [조건문이 참인 경우 값] if 조건문 else [조건문이 거짓인 경우의 값]
ex)

위 사진에서의 조건문과 조건부 표현식의 결과가 일치함을 볼 수 있다
리스트 컴프리헨션(list comprehension)
[표현식 for 항목 in iterable]
표현식: 각 항목을 처리한 후 생성할 값을 지정
for 항목 in iterable: 반복할 대상(iterable, ex) list, string...)
- map함수 사용도 가능
ex)

위 사진에서 두 list의 결과 값이 같음을 알 수 있다
위의 조건부 표현식과 리스트 컴프리 헨션을 통해 식을 간단히 표현할 수 있다
이 둘을 함께 조합하여 사용하는 것도 가능하다

else는 디폴트가 아니기 때문에 생략할 수 있다
NumPy(넘파이)
- 대수, 행렬, 통계 등 수학 및 과학 연산을 위한 라이브러리
- ndarray라는 다차원 배열을 데이터로 나타내고 처리하는 데 특화
- 실행 속도가 빠르고 짧고 간결한 코드 구현이 가능하다
내부적으로 c로 구현
- Numpy는 외부 라이브러리이므로, 설치 후 사용할 수 있다


NumPy 배열과 파이썬 리스트의 차이
- 파이썬 리스트는 배열에 실제 데이터의 주소가 담겨져 있음
-> 서로 다른 데이터 타입을 리스트 요소로 넣을 수 있음
- NumPy 배열은 실제 데이터가 배열에 들어가 있음
- 리스트는 데이터를 읽고 쓰기에 numpy보다 시간이 많이 소요됨
-> 대량의 배열 연산 또는 행렬 연산에는 numpy가 유리

Numpy Array
- numpy는 다차원 배열 지원
- numpy array는 한가지 자료형 데이터를 요소로 갖는다
1차원: vector
2차원: matrix
3차원 이상: tensor
numpy 배열 직접 생성
리스트 데이터를 넘파이 배열로 바꾸어 생성
np.array(리스트)
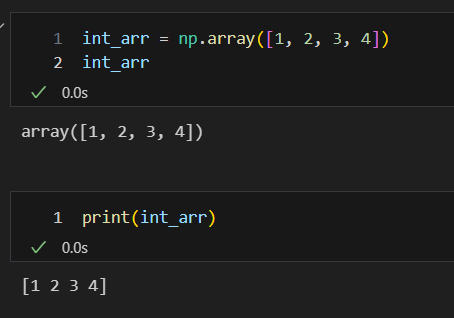
array를 생성하면 다음과 같다. 이를 기존의 list와 비교하여 보면, ','가 없음을 알 수 있다.

numpy로 만든 array의 type을 출력하여 보면 다음과 같다

여기서 ndarray는 다차원 배열을 의미한다
배열의 범위를 지정하여 생성
시적 인덱스부터 시작하여 끝 인덱스 전까지 간격만큼 더해 넘파이 배열 생성
np.arange(시작 인덱스 : 끝 인덱스: 간격)

numpy 배열에 들어가는 자료형
넘파이 배열에 들어가는 자료형은 한가지 데이터 타입으로 통일되어 처리 된다.
ex)
정수와 문자열이 있는 경우 ->문자열
정수와 실수가 있는 경우 -> 실수


여기서 유의해야 할 점은 안에 list를 넣을 수 없다. list는 여러 개의 데이터를 넣는 자료형이라 그 종류가 다르기 때문이다. 에러를 살펴 보면 다음과 같다

2차원 배열 생성
- 2차원 배열은 행렬(matrix)라고 한다
- 가로줄은 행(row), 세로줄은 열(column)

3차원 배열 생성
- 3차원 이상의 배열은 tensor라고 한다

배열의 차원과 크기
넘파일배열명.ndim : 차원을 알려줌


넘파이배열명.shape


1차원 배열에서는 (4,)이런식으로 나타내는데
.shape은 배열의 각 차원의 크기를 나타내는 튜플이기 때문에 (4)는 단순히 정수로 인식되어 차원을 구분하기 위해 (4,)으 로 표기 한다
사실, 기존의 방법으로 행의 개수와 열의 개수를 구하는 방법이 있다

len을 활용하여 행과 열을 구할 수 있다. 그러나 이러한 벙법은 추천하지 않는다
넘파이배열명.size
- 원소의 개수를 구할 수 있다
넘파이배열명.reshape(크기)
- 인수 중 하나에 -1을 주면 알아서 배열을 만들어 준다
- 인수 중 하나에 -1을 주면 알아서 차원을 만들어 준다



행렬을 다양한 형식으로 바꿀 수 있다. 이때, 숫자로 나누어 떨어질 수 없으면 error가 뜨게 된다.(원소가 모자라거나 남을 경우 error)

넘파이 연산
- shape이 같다면 덧셈, 뺄셈, 곱셈, 나눗셈의 연산을 할 수 있다
list 에서는 + 연산이 가능한데, 이는 list 내의 값을 더해주는 것이 아니라 두 개의 list를 연결해주는 것이다
- 벡터화 연산이 가능하다
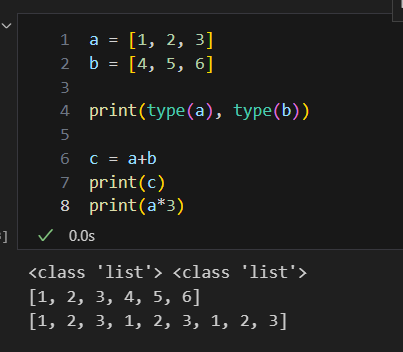
list 연산의 경우, list끼리는 +연산만 가능하며 이는 두 리스트를 연결하여 준다. 또한 숫자와는 * 연산을 사용할 수 있는데, 이 경우 반복 출력된다는 사실을 알 수 있다

반면, array의 경우, 각 원소들끼리 연산되며 벡터 연산 또한 가능하다는 사실을 알 수 있다.
배열의 범위와 개수를 지정하여 생성
시작인덱스부터 끝인덱스까지 n개의 요소를 갖는 넘파이 배열을 생성
np.linespace(시작인덱스 : 끝인덱스 : 개수n)
득별한 값을 갖는 배열 생성
np.zeros()

np.zeros를 사용하면 디폴트로는 실수 값으로 뽑히게 된다. 이를 변경하려면 dtype(data type) 옵션을 사용하면 된다.

이 외에도 행렬 형태로 출력할수도 있다.

np.ones()

np.eye()

np.eye의 경우, 함수 안의 수만큼 1이 출력된다. 즉, n행이 출력됨을 알 수 있다
array의 인덱싱

array에서도 음수 인덱싱을 지원한다.
2차원 배열에서는 다음과 같이 요소를 출력할 수 있다

전체 행을 뽑고 싶은 경우 행 인덱스만 생략하고 열 인덱스는 생략이 가능하다

하나의 열을 뽑고 싶은 경우 아래와 같이 할 수 있다

즉, 파이썬에서는 대괄호 두개를 사용하지 않고 ','를 통해 행과 열 인덱스에 접근이 가능하다

Fancy indexing(팬시 인덱싱)
- 데이터베이스의 질의(Query) 기능을 수행
- 대괄호([]) 안의 인덱스 정보로 숫자나 슬라이스가 아니라 위치 정보를 나타내는 또 다른 ndarray 배열을 받을 수 있다
- Boolean 배열 방식과 정수 배열 방식
1) boolean fancy indexing 방식

원하는 데이터만 필터링할 수 있음을 알 수 있다. 배열의 크기가 같지 않으면 에러가 난다
fancy idexing에서는 인덱스에 배열을 넣을 수 있다는 것으로 생각할 수 있다. 즉, 다음과 같은 형식도 가능하다

즉, 인덱스에 boolean을 결과 값으로 갖는 수식을 넣을 수 있다

따라서 위와 같이 어떤 조건을 만족하는 인덱만을 가져올 수 있다
2) 정수 배열 indexing
인덱스 배열의 숫자들이 원래 배열의 인덱스를 가리킨다
- 원래 배열의 크기와 인덱스 배열의 크기가 달라도 상관없음

또한, 같은 인덱스를 여러번 뽑을 수 있으며, 순서를 바꿀 수도 있다

2차원 fancy indexing

파이썬에서 , 앞은 행을, 뒤는 열을 의미한다. 즉, :, 이라 하면 모든 행에 대하여 [0, 3] 0번과 3번 열을 뽑아낸 새로운 행렬을 만들겠다는 의미이다.
또한 위치 변경도 가능하다

위 사진을 살펴보면, 첫번째 [2, 0, 1]은 행을 의미하므로 2번 인덱스의 행을 맨 처음으로 0번 인덱스의 행을 두 번째로, 1번 인덱스의 행을 세번째로 번경하였음을 알 수 있다.

::-1의 경우 역순으로 출력하여 주기 때문에, 모든 행에 대하여 각 열을 역순으로 출력한 결과가 나옴을 알 수 있다.
Pandas(판다스)
Pandas(Python Data Analysis Library)
- 데이터를 조작/분석하기 위한 라이브러리
- 다양한 데이터 분석 함수 제공
- 행과 열로 이루어진 데이터 객체를 만들고 다룰 수 있다.
판다스의 공식 사이트는 다음과 같다
pandas - Python Data Analysis Library
pandas - Python Data Analysis Library
pandas pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language. Install pandas now!
pandas.pydata.org
Pandas 데이터 구조
시리즈(Series)와 데이터프레임(DataFrame)이 있다
1) 시리즈(Series)

- 1차원 배열의 형태
- 한가지 형의 데이터로 구성
- 인덱스는 문자로 지정가능, 디폴트는 숫자 0부터 시작
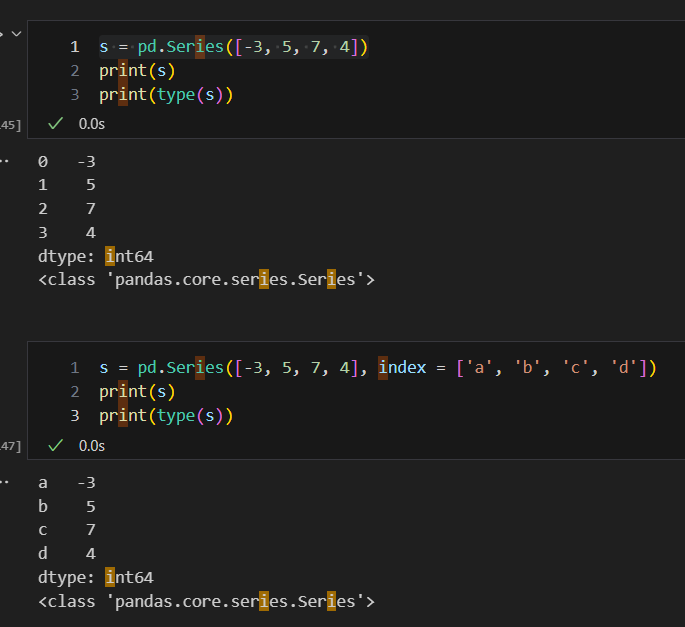
series는 임의로 인덱스 설정이 가능하다

series의 인덱스와 values를 따로 볼 수 있다. 또한, index의 데이터 타입이 object 임을 알 수 있다

인덱스로 값을 접근하고 싶은 경우, 인덱스 명이나 숫자(자리)로 접근할 수 있다. 이때, 숫자로 접근할 때, 경고가 뜨는 것을 확인할 수 있는데, 버전이 달라질 경우, 숫자로 지원하지 않을 수 있음을 경고하고 있다.
2) 데이터 프레임(Data Frame)

- 2차원 배열의 형태
- 인덱스와 칼럼이라는 두 가지 기준에 의해 표 형태처럼 데이터가 저장
- 시리즈가 합쳐진 형태
- 이중리스트나 딕셔너리로 만들 수 있다
- 딕셔너리로 데이터 프레임을 만들면, 키(key)가 칼럼명으로 지정되어 만들어진다

이에 대한 값을 출력하기 위해서는 다음과 같은 코드를 활용할 수 있다.
또한, 다양한 방법으로 데이터에 접근할 수 있다

index, columns, values

index의 값, column의 값, values의 값 또한 보여준다.
DataFrame의 정보를 보고 싶으면 다음과 같이 info()를 활용할 수 있다

info()에서는 null 값이 얼마나 들어있는 지를 확인할 수 있다.
set_index()
일부를 index로 지정하는 것 또한 가능하다

pandas를 활용하여 파일 읽고 편집
excel이나 csv 등의 파일을 열고 편집하는 것이 가능하다

목록을 보면 다양한 형식의 파일을 읽을 수 있는 것을 알 수 있다.
ex)
csv 파일을 읽어온다고 가정하면 다음과 같이 불러올 수 있다.
pd.read_csv(파일경로)

여기서, 같은 디렉토리에 있을 경우, 파일명만 적어주면 되지만, 그렇지 않을 경우 파일의 경로를 적어주어야한다.
또한, 보이는 숫자의 형식을 바꿀 수 있다.
pd.options.display.float_format = '실수 형식'.format

head()
앞에서 부터 n개를 출력하는 함수이다. 데이터가 많을 경우 사용한다. head(3)의 경우, 데이터를 위에서부터 3개 출력한다.
디폴트는 5개이다

tail()
뒤에서 부터 n개를 출력하는 함수이다. 디폴트는 5개이다.
describe()
대표값들을 보여준다(평균, 최소, 표준편차 등). 계산할 수 있는 값들만 출력됨을 알 수 있다.

unique()
특정 칼럼을 뽑아 그 종류를 출력하여 준다(R의 level과 유사)

value_counts()
각 종류별 개수를 알고 싶은 경우 사용한다

nlargest()
큰 순서대로 자료를 정렬하고 싶은 경우 사용한다. 디폴트로 상위 5개를 보여준다

데이터프레임 전체를 정렬할 수도 있는데, 이때 정렬 기준과 원하는 데이터의 수를 정해주어야 한다

데이터의 일부만을 가져오기
해당 열만을 지정하여 전체 데이터의 일부 열만을 가져올 수 있다

특정 행만을 가져오는 것 또한 가능하다

iloc(Positional Indexing)
- 위치를 통한 인덱싱
데이터프레임명.iloc[행번호, 열번호]

하나의 행만을 가져오는 것이 가능하다. 이때, 하나의 행 또는 열을 가져오면, 이는 series가 된다

fancy indexing이 가능한데, 여러 개의 행 또는 열을 같이 가져오면 이는 DataFrame 이 된다. 또한, slicing 이 가능하다.

loc(Label based Indexing)
- 라벨을 통한 인덱싱
데이터프레임명.loc[인덱스명, 컬럼명]
인덱스가 숫자가 아닌경우, 그 이름을 활용하여 data를 가져올 수 있다
이때의 유의점은, 숫자와는 다르게 끝의 범위가 포함됨을 알 수 있다.

이를 행과 열 모두에 적용하여 데이터에서 원하는 특정 영역을 추출할 수 있다

isnull()
null 값이 있는 경우, 에러가 날 수 있기 때문에 해당 값을 찾는 것이 중요하다
우선, info()를 통해 null이 있는 열을 알 수 있다. 이를 활용하여 null이 있는 행을 찾을 수 있다.

isnull을 활용하여 어디에 null이 있는 지 확인할 수 있다.
이에 대한 리턴 값이 boolean이기 때문에 fancy indexing으로 null인 행을 출력할 수 있다

또한 null값의 개수를 sum으로 계산할 수 있다

이렇게 null의 위치를 찾으면, 0으로 채울지, 평균으로 채울 지 등 null 데이터를 어떻게 다룰 지 결정할 수 있다
이외에도 여러가지 조건을 활용하여 데이터의 일부를 가져올 수 있다

loc[]를 활용하면 다음과 같다

유의할 점을 살펴 보면,'

해당 문법은 불가능한데, 이는 boolean 값이 아니기 때문이다.

따라서 위와 같이 해주어야 한다.
오름차순으로 데이터를 정리하고 싶은 경우 다음과 같이 하면 된다

내림차순으로 정리하고 싶은 경우, 옵션 ascending = False 로 하면 내림차순으로 정리할 수 있다

기존의 데이터 프레임을 수정
다음과 같이 데이터 프레임을 수정할 수 있다

기존의 데이터 프레임에 없는 정보는 추가할 수 있다

데이터 프레임을 벡터 연산이 가능하기 때문에 데이터의 편집을 연산으로 수행할 수 있다

column의 이름을 바꾸는 것또한 가능하다

데이터 프레임과 데이터 프레임을 합치고 싶은 경우, concat을 사용한다.
기존의 데이터 프레임에서 삭제
drop()
기존의 행 또는 열을 삭제하고 싶은 경우 사용할 수 있다.

drop 시의 유의 점은 자동으로 기존변수에 저장되는 것이 아니기 때문에 변수에 저장해야 한다는 것이다. 즉, 변수에 덮어쓰거나 다른 변수로 저장해주어야 한다. 만약, 한번에 이를 수행하고 싶은 경우 옵션을 사용할 수 있다.

열도 마찬가지로 삭제해 줄 수 있는데, inplace 옵션을 True로 하면 자동으로 해당 변수에 저장이 된다.
null값 다루기 - 삭제
dropna()
null값이 있는 곳을 삭제할 수 있다. 디폴트로는 행단위로 삭제된다(null이 포함된 행이 삭제)
만일, 열을 삭제하고 싶으면, axis =1로 지정하여 주면 된다
이때, axis는 축이라고 생각하면 된다
행은 axis = 0,
열은 axis가 1이다

null값 다루기 - 다른 값으로 채우기
fillna()
1) 0으로 채우기
데이터프레임명. fillna(0)

2) 이전 값으로 채우기
method = 'ffill'

이전 값으로 null값을 채우기 때문에 원더우먼의 재산 현황이 스파이더맨의 재산 현황과 동일하게 채워졌음을 알 수 있다
3) 이후 값으로 채우기
method = 'bfill'

이후 값으로 null값을 채우기 때문에 토르의 재산 현황이 스파이더맨의 재산 현황과 동일하게 채워졌음을 알 수 있다
4) 평균으로 null값 채우기

평균으로 null값을 채우기를 원할 경우, mean() 함수를 활용할 수 있다
파이썬 데이터 분석
- 아르테미스 달탐사-
데이터분석의 5단계

1. 문제정의
-현재 상황에 따른 문제점 파악
- 미래 개선될 점에 대해서 분석, 주제 정의
2. 데이터 수집
-문제 정의에 다라서 분석에 필요한 데이터 선택
- 데이터 수집
3. 데이터 가공
- 확보한 데이터 관찰 및 기초 데이터 분석
-분석에 필용한 데이터 칼럼 추가 및 가공
4. 데이터 분석
-문제 정의를 반영한 데이터 분석
-연관될 수 있는 다른 데이터의 수집, 연결 및 분석
5. 시각화 및 탐색
-데이터 분석을 반영할 수 있는 시각화
-문제 정의에 맞춘 해결 방안 도출
아르테미스 달탐사
- 달을 탐사하려 한다고 가정
- 가져올 수 있는 암석의 양이 제한되어 있기 때문에 어떠한 암석을 얼마만큼 가져와야 할 지 정해주는 것이 목적
문제 정의
- 달 탐사 및 달 암석 채취시 문제점 파악
- 미래의 달 탐사 및 암석 채취 시 개선될 점에 대해 분석 및 주제 정의
데이터 수집
- 암석 샘프 데이터에 관한 사이트를 알아보고 데이터를 수집
https://curator.jsc.nasa.gov/lunar/samplecatalog/index.cfm
+ 깃허브에서 데이터 다운로드
- 문제 정의에 따라 분석에 필요한 데이터 선택
- 모든 아플로 달탐사에서 채취된 암석 샘플 데이터 수집
데이터 가공
- 암석 샘플 데이터를 읽어들이고 관찰
- 칼럼 변환
- 아폴로 임무별 데이터프레임 만들기
- 필요한 컬럼추가
데이터를 불러와서 정보를 확인하면 다음과 같다
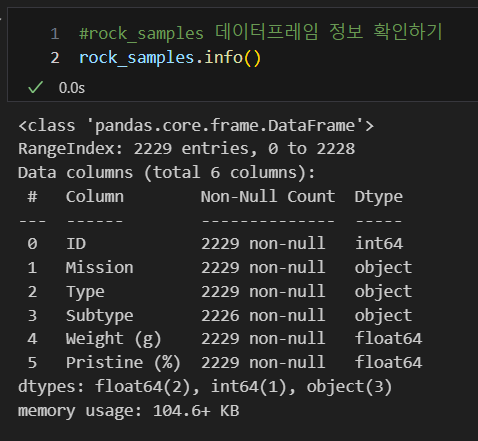
Subtype에 널 값이 있음을 알 수 있다.
정보의 요약을 보면 다음과 같다

남아있는 퍼샌트 백분율인 Pristine이 180%이므로 데이터에 대한 의문이 생길 수 있다. 그럴 경우, 데이터의 원본으로 돌아가 데이터의 의미가 무엇인지 등 다시 살펴보아야 한다
100%가 넘는 컬럼들을 살펴보면 다음과 같다

오늘의 간단한 후기
파이썬에서 흔히 접할 수 있는 numpy와 pandas 모듈에 대해 공부를 하는 시간을 가졌다. 여러 가지 방식으로 데이터를 가공할 수 있다는 장점이 파이썬은 있는 것 같다. R과 유사한 부분도 있고 다른 부분도 있다. 여러가지 메소드 들이 있기 때문에 익숙해지기 위해서는 시간이 걸릴 것 같다. 다음시간 부터 본격적으로 아르테미스 달탐사 등 여러 데이터들을 분석해 볼 수 있는 것이 기대된다.
출처
[1] NASA, "Lunar sample catalog," NASA Curator, 2024. Available: https://curator.jsc.nasa.gov/lunar/samplecatalog/sample_results_list.cfm. Accessed: Dec. 27, 2024.
[2] Dr. G, "Over The Moon: Sample return data," GitHub, 2024. Available: https://github.com/drguthals/learnwithdrg/tree/main/OverTheMoon/sample-return/data. Accessed: Dec. 27, 2024.
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(인선미 강사님)을 기반으로 제작되었습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다.
'MS AI school 6기' 카테고리의 다른 글
| [Microsoft AI School 6기] 12/31(10일차) 정리 - 유성우, Bike (0) | 2024.12.31 |
|---|---|
| [Microsoft AI School 6기] 12/30(9일차) 정리 - 달 탐사, 유성우 (2) | 2024.12.30 |
| [Microsoft AI School 6기] 12/24(7일차) 정리 - 내장 함수, 람다 함수, 모듈, 클래스 (2) | 2024.12.24 |
| [Microsoft AI School 6기] 12/23(6일차) 정리 - Dictionary, Tuple, 함수 (0) | 2024.12.23 |
| [Microsoft AI School 6기] 12/20(5일차) 정리 - 반복문, list (1) | 2024.12.20 |



