

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- microsoft
- MS
- 마이크로소프트 ai 스쿨 6기
- 마이크로소프트 ai school 6기
- 마이크로소프트
- 마이크로소프트 ai 스클
- msai
- microsoft ai school
- 마이크로소프트 AI
- microsoft ai school 6기
- 마이크로소프트 ai 스쿨
- micsrosoft ai
- microsoft ai
- Today
- Total
연랩
[Microsoft AI School 6기] 12/30(9일차) 정리 - 달 탐사, 유성우 본문
파이썬 데이터 분석
아르테미스 달탐사
- OverTheMoon_달탐사
목표: 어떠한 암석을 얼마만큼 가져와야 하는가(기존의 암석 수집량과 사용량을 바탕으로)
데이터의 자료형
개별 컬럼은 정수, 실수, 문자, 날짜 등의 자료형(data type)을 가진다
- object: 문자 또는 문자열(' '으로 구분)
- int64: 정수
- float64: 실수
- datetime64: 날짜(' '으로 구분)
- boolean: 참/거짓
데이터 컬럼 살펴보기

ID: NASA에서 샘플을 추적하는데 사용하는 고유 ID
Mission: 샘플이 수집된 아폴로 임무
Type: 암석 샘플 종류
Subtype: 구체적인 암석 샘플 종류
Weight (g): 암선 샘플 질량 (g)
Pristine(%) : 남아 있는 암석 샘플 백분율
위의 info를 보면 Subtype에 null값이 있음을 알 수 있다. pandas에서 isnull()을 사용하면 다음과 같다

데이터의 양이 너무 많아 어디가 null값인지 확인하기 어려움으로 isnull.sum()으로 null값의 위치를 확인할 수 있다,

데이터 전처리
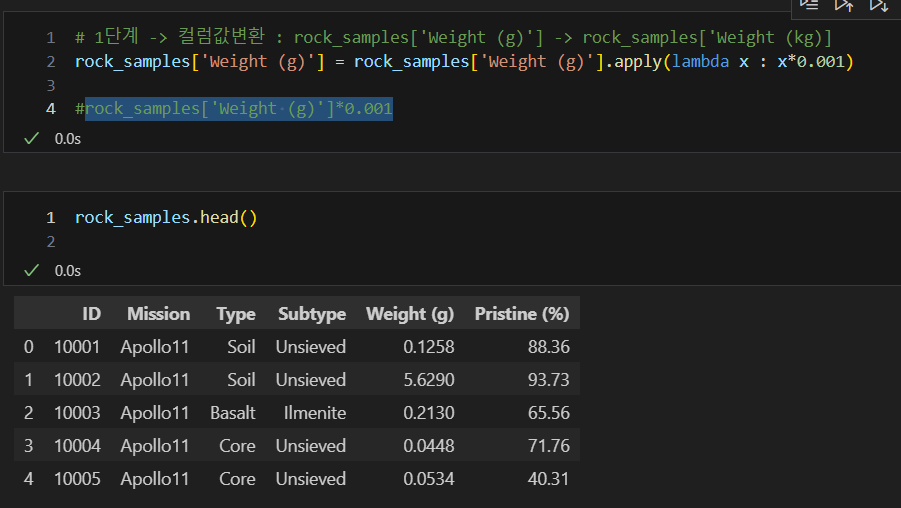
weight(g) -> weight(kg)
g단위의 칼럼을 kg 단위로 바꾸기 위해서는 value에 0.001을 곱하고, col명을 weight(kg)으로 바꾸어 주어야 한다.
1) 칼럼값 변환
칼럼에 변환을 적용하기
df.apply(함수명)
- 데이터프레임의 칼럼, 시리즈 또는 데이터프레임 전체에 대해 함수를 적용

rock_samples['Weight (g)']*0.001 를 적용해도 같은 값이 나온다.
둘 중 무엇으로 연산을 하여도 변수에 적용을 따로 해주어야 한다. 그후, 확인을 하면 다음과 같다
2) 칼럼명 변환
df.rename(columns = {변경전 컬럼명 : 변경후 컬럼명}, inplace = True)
복수 개의 column 명을 변경할 수 있다
이때, inplace = True를 적용하기 전에 미리 확인을 하고 옵션을 적용하는 것을 추천한다

혹은 다음을 통해서도 변경이 가능하다
df.columns = ['ID', 'Mission', 'Type', 'Subtype', 'Weight (kg) ', 'Pristine (%)']
Mission 별로 암석의 중량을 분리하여 살펴보자
이를 위해서 우선, 어떤 mission들이 있는 지 살펴보아야 한다

또한 value_counts를 통해 임무 별로 가져온 암석의 양을 알 수 있다

missions라는 새로운 데이터 프레임을 만들어 각 임무 별 정보를 저장하기 위해 missions에 'Mission' 칼럼을 만들고 각 임무를 넣은 칼럼은 다음과 같다

3) 그룹핑
rock_samples에서 각 미션별로 중량을 살펴보기 위해서 groupby()를 사용할 수 있다.

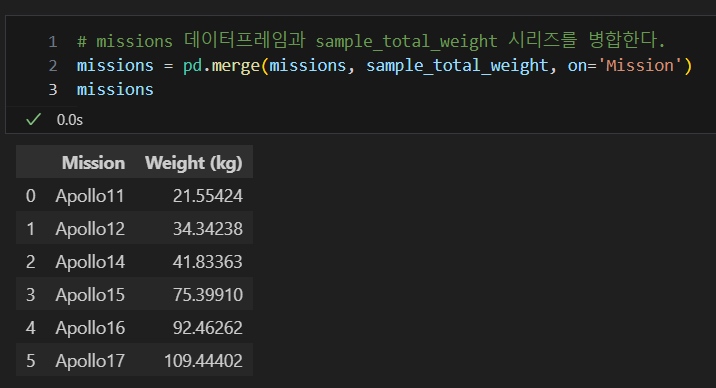
위의 사진에서 보면, 중량을 Mission 단위(그룹)으로 묶어서 출력하였음을 알 수 있다. 이를 sample_total_weight에 저장하고 이를 missions 데이터 프레임에 결합하여 보자
4) 데이터프레임과 시리즈 연결
pd.merge(df, s, on = '시리즈 인덱스와 같은 데이터프레임의 컬럼명')
병합을 할 때에는 기준이 있어야 한다. 그 기준을 on ' ' 에 지정하여 주면 된다.
데이터프레임과 데이터프레임도 연결이 가능하다.(df+df, s+s, s+df 가능)
JOIN이라고 이해하면 된다...
sample_total_weight.values를 하면 해당 값을 불러올 수 있기 때문에 이를 이용하여 missions 데이터 프레임에 값을 추가하는 방법도 존재한다.
Weight (kg)의 컬럼명을 Sample weight (kg)으로 변경하면 다음과 같다

다음으로 임무 간 중량 차이를 구해보도록 하자
5) column에서 각 값 별 차이
diff()

임무 별로 가져온 암석의 중의 차이를 비교 하기 위해 diff()를 사용하였다. 이때, 맨 위에 NaN이 존재하는 이유는 그 전 값이 없어 차이를 구할 수 없기 때문이다. 이를 missions에 추가하면 다음과 같다

6)결측치 0으로 채우기
Apollo11은 이전 값이 없으므로 '0'으로 값을 채우도록 한다.

missions = missions.fillna(0)로도 결측값을 0으로 채울 수 있다.
달 탐사선 중량 데이터 추가
NASA - NSSDCA - Master Catalog - Spacecraft Query
Apoolo 달탐사 임무에 사용된 Saturn V 로켓에는 두 가지 모듈이 있다
승무원 영역(Crewed Area)
달 모듈(Lunar Module):
- 달 궤도에 도달한 후 명령 모듈에서 분리
- 달 표면에 착륙
- 우주 비행사 수송
- 우주 비행사는 달에서 수집된 암석 샘플을 여기에 싣고 명령 모듈로 귀환
명령 모듈(Command Module):
- 우주 비행사가 생활하는 모듈
- 우주비행사와 수집된 암석 샘플이 이 모듈에 실려 지구로 귀환
이러한 모듈의 무게를 고려해야한다. 즉, 아폴로 임무별로 달 모듈과 명령 모듈의 정보를 추가해야 달 탐사선을 위한 정확한 중량 계산이 가능하다
따라서 missions 데이터프레임에 각 모듈의 이름, 중량, 중량 차이에 관한 칼럼을 추가할 예정이다
Luna module 정보 추가
1) Luna module 이름과 중량 정보 추가
우선 달모듈이름과 달모듈중량 column을 추가하면 다음과 같다

2) Luna module 중량 차이(아폴로 임무별)
diff()를 사용하여 아폴로 임무별로 달 모듈 중량 차이를 구해서 데이터 프레임에 추가하면 다음과 같다

여기에서 발생한 결측치를 0으로 채우면 다음과 같다

Command Module 정보 추가
Luna module에서 수행한 것과 마찬가지로 Command module에서 수행하면 다음과 같다
1) Command module 이름과 중량 정보 추가
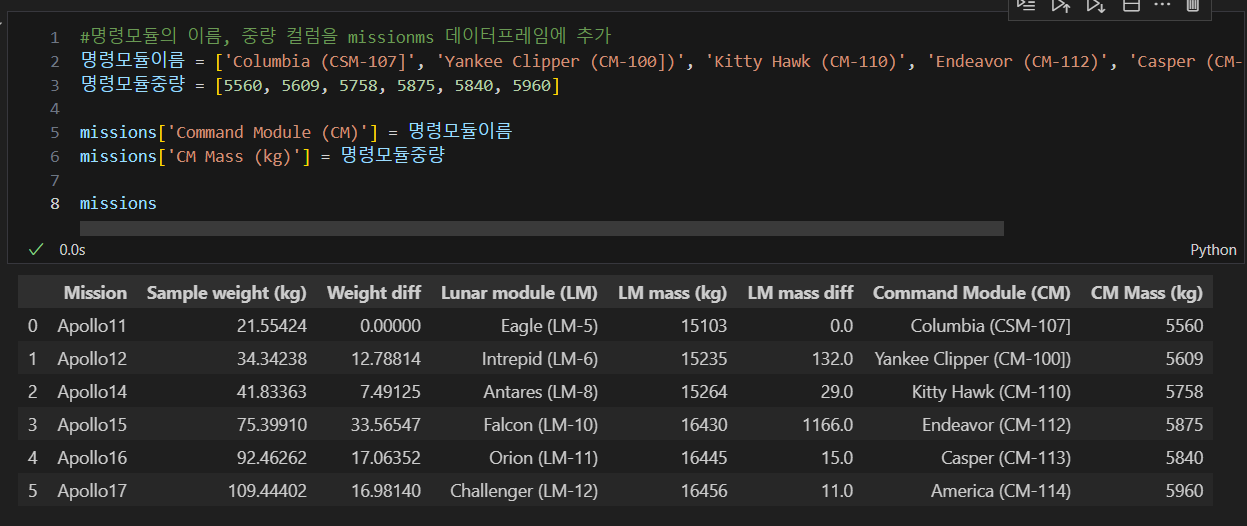
2) Command module 중량 차이(아폴로 임무별)


Crewed Area(승무원 영역)
승무원 영역은 달 모듈과 명령 모듈을 합친 영역이다.
1) 달 모듈과 명령 모듈 중량을 합한 값을 새로운 칼럼으로 만들어 missions 데이터 프레임에 추가
달 모듈과 명령 모듈 중량을 합한 값을 'Total Weight (kg)'라는 새로운 칼럼으로 생성하여 missions에 추가하면 다음과 같다
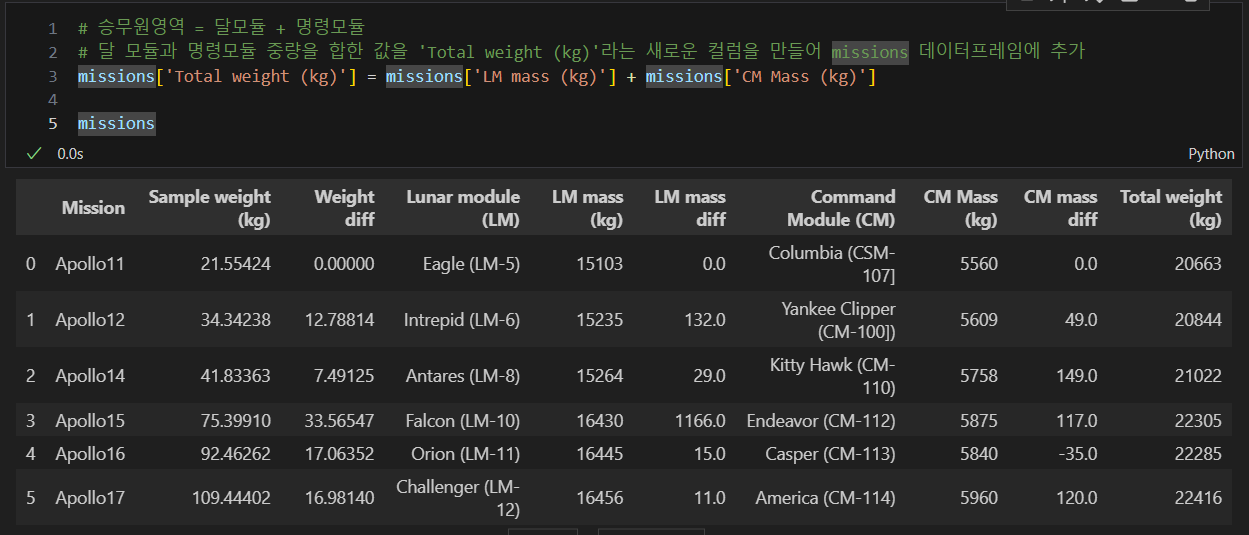
2) Crewed Area(Total weigth (kg)) 중량 차이(아폴로 임무별)
앞선 절차와 마찬가지로 diff를 구하면 다음과 같다
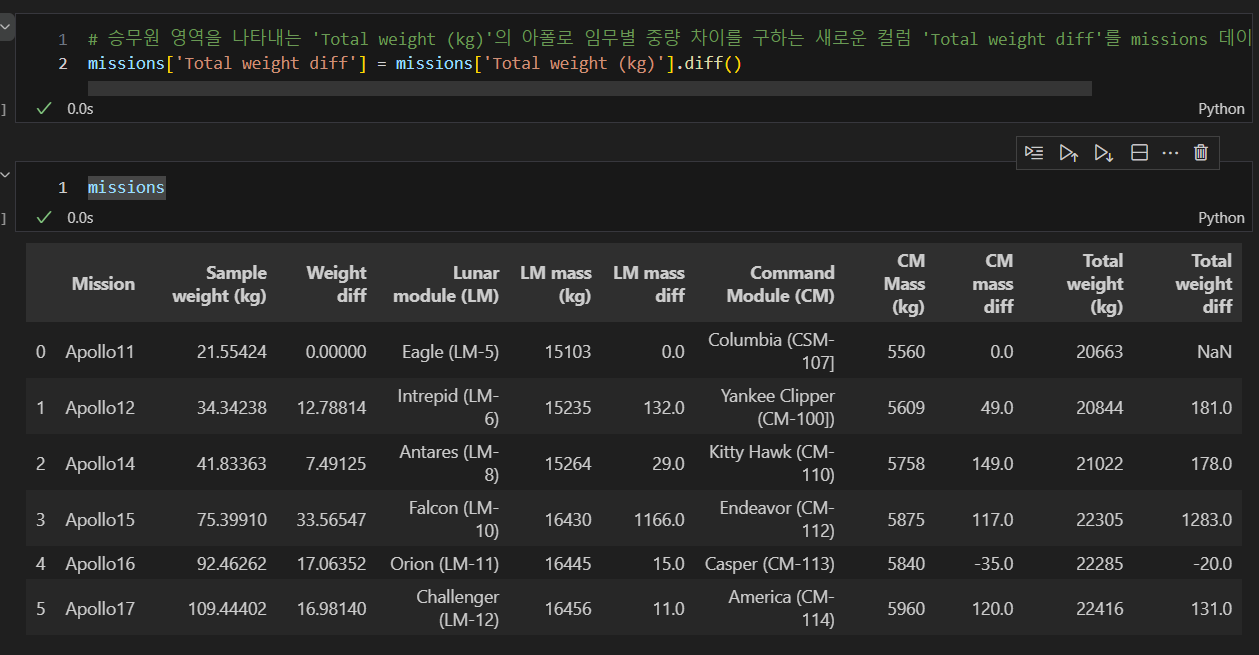
결측값을 0으로 채우면 다음과 같다

각 영역에 대한 정보를 구한 것을 토대로 여러가지 비율을 구해보도록 한다.
비교할 값/기준이 되는 값
페이로드에서 승무원 영역이 차지하는 비율

승무원 영역에서 암석 샘플이 차지하는 비율

페이로드에서 샘플이 차지하는 비율

artemis_mission 데이터프레임 만들기
딕녀너리로 데이터프레임 만들기

missions 데이터프레임에서 'Crewed area : Payload', 'Sample : Crewed area', 'Sample : payload' 의 평균값을 구해보면 다음과 같다

데이터프레임에 Sample weight from total (kg)' 컬럼과 .Sample weight from payload (kg)' 컬럼을 추가한다. artemis_mission['Sample weight from total (kg)'] = artemis_mission['Total weight (kg)']*Sample_CrewedArea_ratio와
artemis_mission['Sample weight from payload (kg)'] = artemis_mission['Payload (kg)']*Sample_Payload_ratio를 써서 계산하며, 이 둘의 평균을 계산한 칼럼 또한 추가하면 다음과 같다

아르테미스 임무에서 가져올 암석 종류 구하기
Weight에 Pristine을 곱해 데이터프레임에 암석 샘플의 남은 양을 나타내는 칼럼 추가

수치 데이터의 통계를 살펴보면 다음과 같다

암석의 평균 무게가 0.16임을 통계를 통해 알 수 있다.
우선, 암석 중 0.16보다 Weight가 큰 샘플을 우선 추출해보도록 하자

다음으로, weight가 0.16보다 크면서 pristine이 50보다 작은 암석을 찾아보도록 하자
즉, 큰 양을 채취했으나 남은 양이 적은 물질을 필터링 해보았다

이러한 조건을 만족시키는 데이터를 모아 데이터 프레임을 만들면 다음과 같다

low_samples = rock_samples.loc[(rock_samples['Weight (kg)'] >= 0.16) & (rock_samples['Pristine (%)'] <= 50)] 이와 같이 loc를 사용하여 추출하는 코드 또한 사용할 수 있다.
info를 통해 확인하면 기준을 만족하는 데이터가 27개 남아있음을 확인할 수 있다

이를 Type 별로 살펴 보면 다음과 같다

Basalt와 Breccia의 샘플이 가장 부족함을 알 수 있다.
이를 바탕으로 low_samples의 Type이 Basalt이거나 Breccia인지 확인하기 위해서는
isin()
을 사용하는 방법이 있다.
isin()안에는 iterable이 올 수 있다.

이를 활용하여 low_samples['Type'] 의 값이 'Basalt'이거나 'Breccia'인 행만 추출해서 needed_samples 데이터프레임을 만들면 다음과 같다

rock_samples 데이터프레임에서 'Type'으로 groupby 해서 암석 샘플의 중량의 합을 구한다. 즉, 아폴로 임무에서 처음부터 수집이 안된 암석을 구한다.
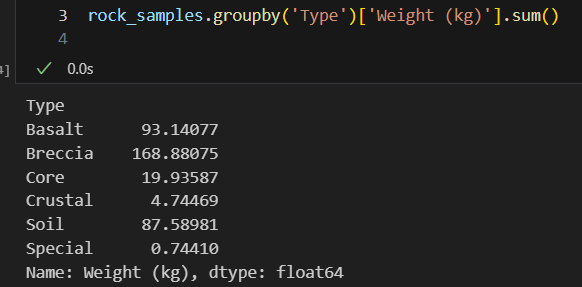
해당 자료를 통해 Crustal과 같은 경우 채취량 자체가 적었음을 확인할 수 있다. 즉, 희귀성이 높다고 볼 수 있으므로 채취할 암석 목록에 포함시키는 방안을 고려할 수 있다
따라서 needed_samples에 crustal을 추가하기로 한다.
concat()
디폴트 값은 axis=0이다
concat([df1, df2])

아르테미스 임무에 전달할 최종 데이터프레임 needed_samples_overview를 만든다
해당 데이터 프레임에는 어떤 암석을 가져와야하는 지와 얼마만큼 가져와야 하는 지를 기록한다
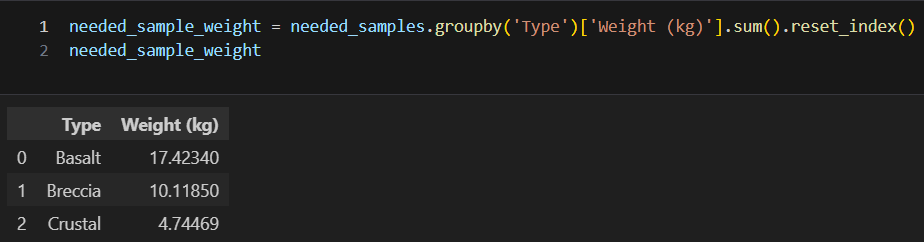
needed_samples_weight에는 암석의 무게가 들어있다. needed_samples_weight와 needed_samples_overview를 병합하면 다음과 같다(데이터프레임끼리의 병합)

merge는 여러번 할 경우 오류가 날 수 있기 때문에 유의해야한다
needed_samples 데이터프레임에서 암석 유형별 중량의 평균을 구하고 needed_samples_overview랑 결합한다

또한 데이터프레임에서 암석 유형별 개수를 구해서 merge한다

그후, 암석유형별로 차지하는 비율을 구해서 'Percentage of rocks'라는 칼럼에 할당하고 이를 artemis_mission의 Estimated sample weight에 곱해 구해야하는 암석의 중량을 구한다. 이를 평균 무게로 나누어 암석의 개수를 구하여 저장하면 다음과 같은 결론을 구할 수 있다.

아르테미스 달탐사
- OverTheMoon_유성우
- 유성우는 관측자의 위치, 관측 시기, 관측 날짜의 달의 위상 등에 따라 유성우를 볼 수 있는 지의 여부가 달라진다
4개의 혜성에서 발생하는 주요 5대 유성우
데처 혜성(Coment Thather) -> Lyids(거문고자리 유성우)
헬리 혜성(Comet Halley) -> Eta Aquaris(에타 물병자리 유성우), Orionids(오리온자리 유성우)
스위프트-터틀 혜성(Comet Swift-Tuttle) -> Perseids(페르세우스 자리 유성우)
템플-터틀 혜성(Comet Tempel-Tuttle) -> Leonids(사자자리 유성우)
유성을 관측을 위해서는 각 유성우가 발생하는 기간과 복사점의 별자리 정보 필요
- 달이 너무 밝은 날에는 유성우 관측이 힘들다
필요한 데이터 정의
유성우 데이터 - 관측기간
- 유성우 이름
- 시작일
- 종료일
- 복사점(별자리)
별자리 데이터 - 관측 가능한 위치
- 시작위도
- 종료위도
도시데이터 - 관측자의 위치
- 도시명
- 위도
달의 위상 데이터 - 관측조건
- 날짜
- 달의 위상
데이터 파일
meteorshowers.csv
moonphases.csv
constellations.csv
cities.csv
의 파일 사용, 해당 파일들을 깃허브에 저장되어 있음
데이터 분석
meteorshowers 데이터를 살펴보면 다음과 같다

이를 살펴보면 월의 이름이 문자형으로 되어 있는 데, 이를 다루기 위해 숫자로 바꾸는 작업이 필요하다. 이는 dictionary를 사용하여 할 수 있다. 또한 map 함수를 사용할 수 있다.

이때, 두번 map하면 NaN이 뜨게 되므로 유의하여야 한다
마찬가지로 다른 데이터의 월명도 숫자로 바꿔준다.
Datetime 형식으로 변환
일자 정보를 Datetime 형식으로 변환한다. startmonth, startday 두 칼럼의 데이터를 이용하여 Datetime 형식으로 만들어야 한다.(2020데이터이므로 년도는 2020으로 고정)
-> 8자리 날짜 포맷으로 만들어야 함
ex) 2020*10000 + 11*100 + 6*1 => 20201106
format = '%Y%m%d' ----> 2020-04-28
pd.to_datetime(숫자, format = '%Y%m%d' )

meteor_showers에 startdate와 enddate 칼럼을 추가하고 info()를 확인하면 다음과 같다

데이터 타입이 datetime으로 되어 있음을 알 수 있다.
마찬가지로 moon_phase 데이터도 변경하여 준다
moon_phase에서 달의 위상 데이터를 숫자로 변환
- 반달은 상현과 하현이 광량이 같으므로 0.5로 동일하게 취급한다.

불필요한 칼럼 삭제
데이터프레임.drop([칼럼이름들........], axis = 1)
칼럼을 삭제하고 싶은 경우, axis = 1
row를 삭제하고 싶은 경우 axis = 0를 하면 된다
오늘의 간단한 후기
데이터 분석을 처음해보는 것이라 익숙치 않아서 쉽지 않았다. 또한 달탐사 파일을 날려먹어서 속상했다...ㅠㅠ 복구 해놓긴 했지만 아까운 마음을 지울 수 없다... 앞으로 백업을 잘 해놓아야 겠다. 데이터 분석을 R에서만 해보았는 데 파이썬의 문법과 같이 사용할 수 있어 기능이 더 많은 거 같았다. 사실 달탐사에서 무엇을 하고 있는 지 길을 잃어서 혼란스러웠다. 데이터 분석을 할 때에는 목표를 확실히 정하고 따라하는 것이 중요할 것 같다.
출처
[1] NASA, "Spacecraft query form," NASA Space Science Data Coordinated Archive (NSSDC), 2024. Available: https://nssdc.gsfc.nasa.gov/nmc/SpacecraftQuery.jsp. Accessed: Dec. 18, 2024.4
[2] Time and Date AS, "Moon phases data (CSV)," Timeanddate.com, 2024. Available: https://www.timeanddate.com/moon/phases/. Accessed: Dec. 18, 2024.
[3] NASA, "Meteor showers data (CSV)," NASA Science: Solar System Exploration, 2024. Available: https://solarsystem.nasa.gov/meteor-shower-calendar/. Accessed: Dec. 18, 2024.
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(인선미 강사님)을 기반으로 제작되었습니다
깃허브 소스코드의 내용을 담고 있습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다.
'MS AI school 6기' 카테고리의 다른 글
| [Microsoft AI School 6기] 1/2(11일차) 정리 - 커리어 멘토링(1) (2) | 2025.01.03 |
|---|---|
| [Microsoft AI School 6기] 12/31(10일차) 정리 - 유성우, Bike (0) | 2024.12.31 |
| [Microsoft AI School 6기] 12/27(8일차) 정리 - NumPy, Pandas (3) | 2024.12.27 |
| [Microsoft AI School 6기] 12/24(7일차) 정리 - 내장 함수, 람다 함수, 모듈, 클래스 (2) | 2024.12.24 |
| [Microsoft AI School 6기] 12/23(6일차) 정리 - Dictionary, Tuple, 함수 (0) | 2024.12.23 |



