

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- microsoft ai
- 마이크로소프트 ai 스쿨 6기
- microsoft ai school 6기
- microsoft ai school
- 마이크로소프트
- 마이크로소프트 AI
- microsoft
- MS
- 마이크로소프트 ai school 6기
- micsrosoft ai
- 마이크로소프트 ai 스클
- 마이크로소프트 ai 스쿨
- msai
- Today
- Total
연랩
[Microsoft AI School 6기] 1/20(23일차) 정리 - MLD, 군집 모델, 분류모델, 회귀 모델 본문
[Microsoft AI School 6기] 1/20(23일차) 정리 - MLD, 군집 모델, 분류모델, 회귀 모델
parkjiyon7 2025. 1. 20. 18:09MS Azure ML Designer를 활용한 군집 모델
프로야구 데이터를 활용한 선수능력 측정 모델 구현

문제 정의
야구 타자의 능력 수치를 바탕으로 내년 스카웃 결정
데이터 준비
주성분 분석(PCA)
주성분 분석(PCA, Principal Component Analysis)
: 데이터를 효율적으로 표현하기 위해 고차원 데이터를 저차원으로 변환하는 차원 축소 기법
-> 과대적합 방지
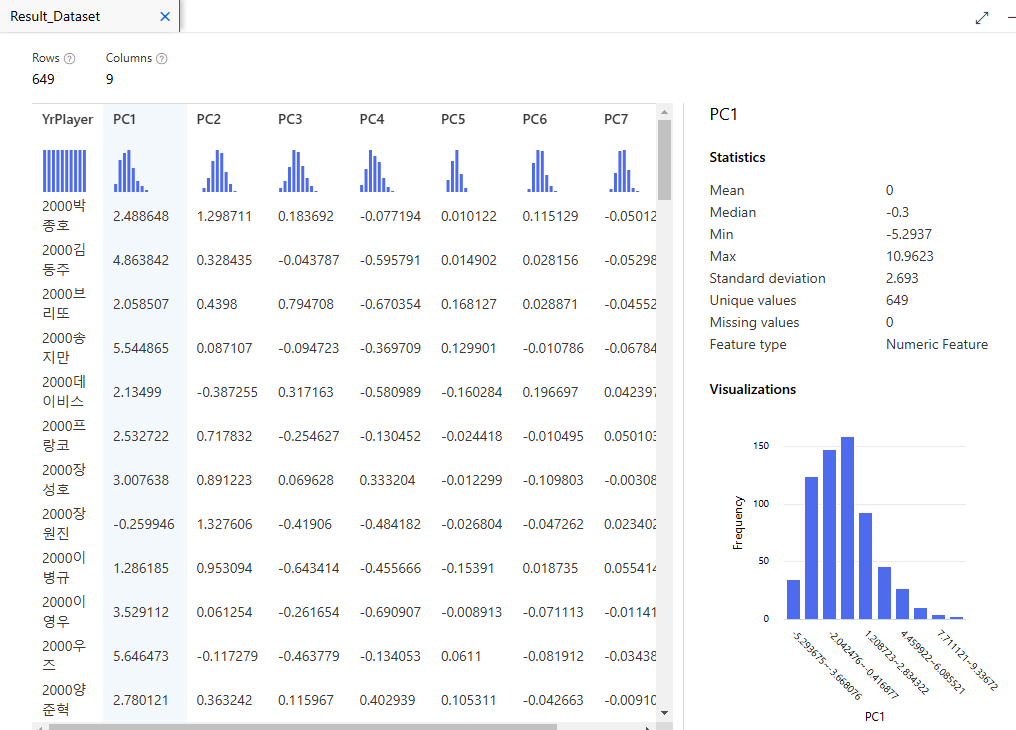
주요 서분의 표준편차를 알아볼 수 있다. 여기에서 주목해야할 것은 Standard deviation이다.
Variance (분산)
- 각 주성분(PC)이 데이터의 전체 분산(variance)에서 얼마나 많은 비율을 설명하는지를 나타냄
- 분산은 데이터의 퍼짐 정도를 나타내며, 주성분은 데이터를 이 퍼짐이 가장 큰 방향으로 정렬
- PCA에서는 분산이 클수록 그 주성분이 데이터를 더 잘 설명한다고 간주
Cumulative Variance (누적 분산)
- 누적 분산은 선택한 주성분들이 전체 데이터 분산을 얼마나 설명하는지의 누적 비율을 의미
- 예를 들어, PC1과 PC2의 누적 분산이 90%라면, 이 두 주성분만 사용해도 데이터의 90% 정보를 유지할 수 있다는 뜻
PCA 주성분 선택
PCI, PC2, YrPlayer 선택
데이터 분리
Sabermetrics 계산 및 데이터 병합 및 분리
Excel 수식을 사용하여 sabermetrics를 계산한 후 Azure Machine Learning Studio Designer에서 2000~2001년 데이터와 2002~2013년 데이터를 병합하여 분석하는 방식으로 실습 진행 예정
데이터 분리
Split Data Component를 사용하여 2000~2013년 데이터와 2014년 데이터를 분리
2000~2013년 데이터 : 594개
2014년 데이터 : 55개
594/649 = 약 0.9152
2000-2013 데이터를 학습 데이터, 2014년도 데이터로 군집 예측
모델링
알고리즘 및 하이퍼 파라미터
K-Means Clustering 사용

모델 학습
분류, 회귀는 그냥 train model
비지도 학습인 clustering은 train clustering model
2000-2013데이터를 이용하여 군집모델 학습

평가
모델 테스트(예측)
Assign Data to Clusters component를 이용하여 2014년 데이터로 군집 예측
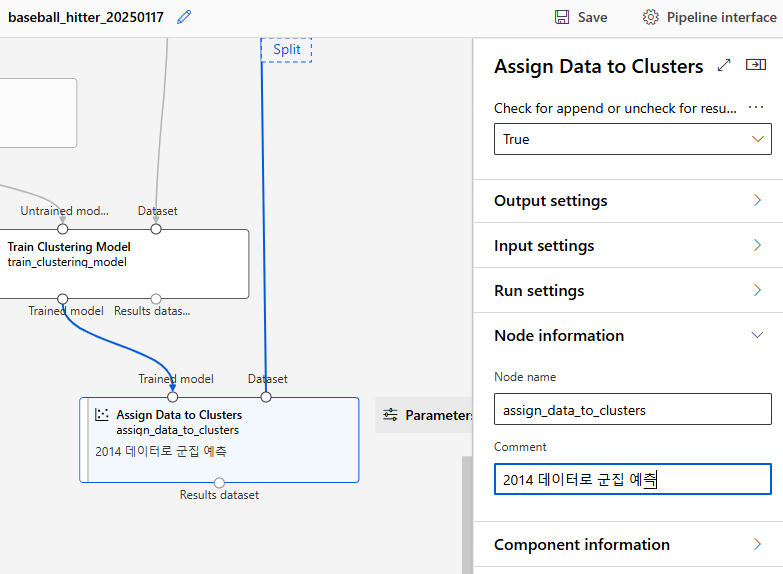
Trained Model로 2000-2013 데이터, Dataset으로 2014 데이터 사용
모델 평가
군집 모델을 평가하기 위하여 Evaluate Model component 사용
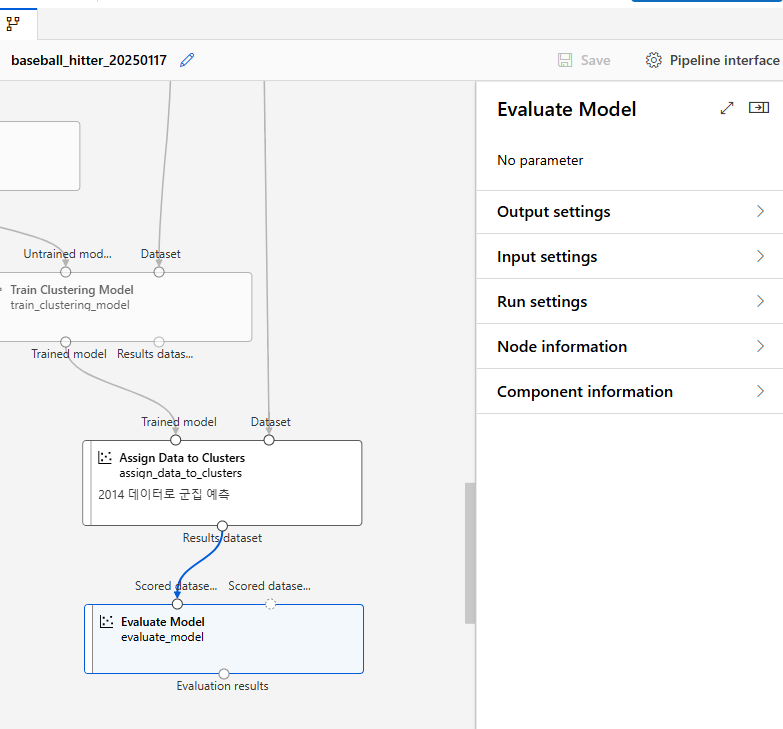
군집 결과 확인
내용 저장 후 Configure&Submit
Jobs > Train Clustering Model 우측버튼 클릭 > Preview data > Result dataset
2000-2013 데이터, 즉 학습된 군집결과를 확인하면 다음과 같다
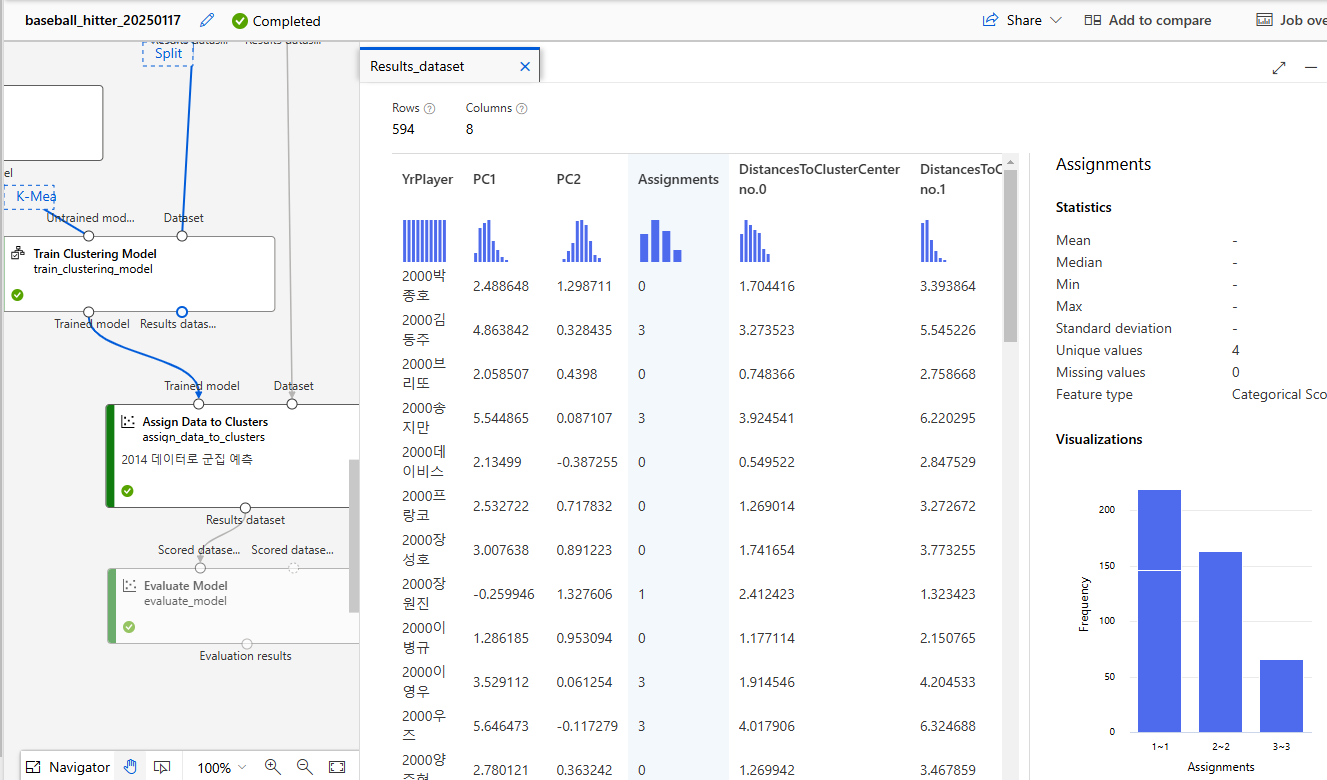
Assignments는 군집 할당(0-3)Distance to CluserCenter는 각 centroid와의 거리
2014년 데이터 군집 예측결과 확인
Jobs > Assign Data to Clusters 우측버튼 클릭 > Preview data > Result dataset

군집 모델 평가 결과 확인
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results
Evaluate Models는
모델 자체의 성능 파악
-> 모델 자체가 잘 구분하였는 지 확인

- Combined Evaluation은 종합 평가
- Average Distance to Other Center: 분리도 - 다른 centroid와의 평균 거리 -> 클수록 좋음
- Average Distance to Cluster Center: 응집도- 군집 중심과의 평균거리 -> 작을수록 좋음
- Number of points: 군집 내의 데이터 개수
- Maximal Distance to Cluster Center: 분산 파악-Centroid에서 가장 멀리 있는 데이터의 거리 -> 클수록 멀리 퍼져 있거나 이상치가 있을 확률이 높음
- Number of Points는 모델 평가(Evaluation) 단계에서 분석이나 평가에 사용된 데이터의 샘플 개수를 의미
추가 실습 : 군집 모델 평가 – K = 4,5 비교
- 형성하는 군집의 수를 비교하기 위한 실습
- 앞서 진행한 군집의 크기 = 4, 이번에는 5로 진행
> Designer > 복사 붙여넣기 가능

k = 5를 추가한 전체 구조는 다음과 같다

군집 모델 결과 확인
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

- Evaluation results 결과에서 k=4와 k=5의 결과를 함께 살펴볼 수 있다
MS Azure ML Designer를 활용한 분류 모델
Random Forest 알고리즘을 이용한 개인 수입 예측 모델 구현
실습 개요 -> 실습 준비 -> 데이터수집/이해 -> 데이터 준비 -> 모델링 평가
실습 개요
배경 및 목표
미국의 인구조사(census) 데이터를 분석하여 개인의 연간 소득을 예측할 수 있는 모델 구현 이진 분류 모델을 통해 연간 소득 5만 달러를 기준으로 개인을 구분하고자 함
알고리즘
- 랜덤 포레스트 사용
-> 앙상블인데 의사결정 나무만을 조합하여 사용
-> 같은 데이터를 계속 주면 결과가 같이 나옴 -> 샘플링하여 다르게 사용
데이터 수집
데이터 출처
Kaggle의 Adult Census Income 데이터세트 이용
-> 데이터 분석 대회가 열리는 곳, 수상 시 메달 제공
데이터 세트의 원 출처 : UCI
Kaggle > 로그인 > Dataset > adult census income 검색 > Dowload
-> csv로 다운로드됨을 알 수 있다
https://www.kaggle.com/datasets/uciml/adult-census-income
Adult Census Income
Predict whether income exceeds $50K/yr based on census data
www.kaggle.com
원 데이터 출처인 UCI에 가면 각 변수에 대한 설명을 상세히 볼 수 있다
Adult - UCI Machine Learning Repository
UCI Machine Learning Repository
Listing of attributes: >50K, <=50K. age: continuous. workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked. fnlwgt: continuous. education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc
archive.ics.uci.edu
- 데이터 세트에 '.'가 포함되어 있는 칼럼은 '_'로 수정
데이터세트 등록
Azure > Data > Create

데이터 수집/이해
데이터 이해
Designer > Create 후 Data에서 adult_census_data 드래그앤 드롭
더블 클릭 > Outputs > Preview Data

경고 :
데이터의 Profile은 10,000개 행에 대해서 보여지고 있으며, Profile 생성 기능을 통해 모든 데이터에 대한 Profile 확인 가능함
-> 이 이상을 보고 싶을 경우
Data > Generate profile > compute instance 결정 후 > Generate
Jobs에서 Profile 생성 작업의 진행상황 확인 가능

> Designer > adult_census_data 더블 클릭 > Outputs > Preview >Profile
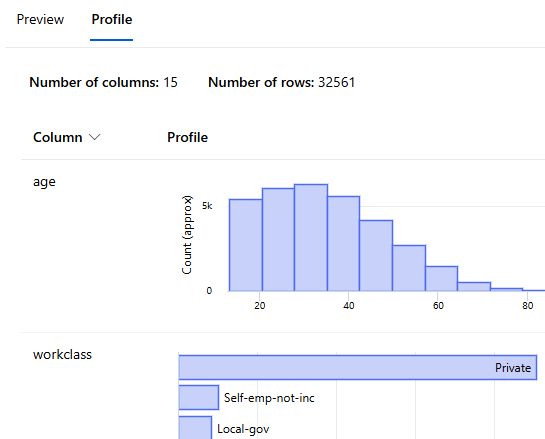
데이터가 제대로 적재되었음을 확인할 수 있다
그 중 missing data를 확인하면 되는데, 잘 정제되어 결측값이 없음을 알 수 있다
각 컬럼의 히스토그램, 형식, 최솟값, 최댓값 등 확인
평균, 표준편차, 분산, 왜도, 첨도, 4분위수 등 통계량 등 확인
Type을 정렬하여 범주형 컬럼 확인(String)
불균형이 심한 칼럼 확인
-> workclass, native_country -> 통계상 유의미 하지 않으므로 삭제 예정
데이터 준비
특성 선택
특성 선택 - 불필요한 컬럼 제외
Designer > Select Columns in Dataset > 더블클릭 > Edit column

누락값 처리 – 데이터 샘플 제거
Clean Missing Data Component > Select Columns in Dataset Component와 연결

누락값이 있을 경우 해당 행을 제거하는 것을 디폴트로 함
- Remove entire row
데이터 변환
String → Category → Indicator value
문자열 데이터 형식을 범주형 데이터로 변경 후, 순서가 없는 범주형 데이터의 경우 indicator value로 변환
String → Category(범주)
> Designer > Edit Metadata
Cleaned datasets를 입력으로 사용하고 선으로 연결

데이터 변환 - Category→Indicator value
문자열 데이터 형식을 범주형 데이터로 변경 후, 순서가 없는 범주형 데이터의 경우 indicator value로 변환
> Convert to Indicator Values

데이터 분리
학습 데이터와 테스트 데이터로 분리
Designer > Split Data
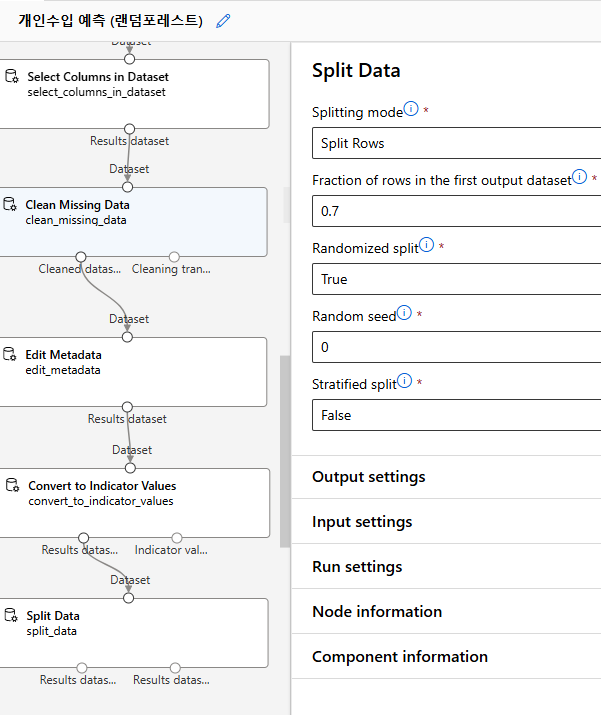
전체 데이터를 학습 데이터 70%, 테스트 데이터 30%로 분리
학습 데이터는 Split Data 컴포넌트의 왼쪽, 테스트 데이터는 오른쪽 링크
모델링/평가
모델링 알고리즘 선택
고객의 대출 가능성 예측은 대출 가능(True) 또는 불가능(False) 2가지 유형으로 예측하므로 머신러닝 중 분류(Classification) 유형으로 결정
>Designer > Two-class Decision Forest

모델 학습(훈련)
분류 모델에서는 정답(라벨, Label)으로 사용할 컬럼을 지정해야 함 - income
> Designer > Train Model

모델 테스트
> Designer > Score Model
모델 테스트를 위해 1) 테스트 데이터세트 및 2) 훈련된 모델이 필요
Split Data의 우측 (테스트 데이터)과 훈련이 끝난 Trained Model을 입력 값으로 적용

모델 평가
> Designer > Evaluate Model

실행 후 결과 확인
save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

MS Azure ML Designer를 활용한 회귀 모델
선형회귀를 이용한 자동차 가격 예측 모델 구현
실습 준비
데이터 제공 사이트
UCI Repository의 Automobile 데이터세트 이용
Automobile - UCI Machine Learning Repository
UCI Machine Learning Repository
Attribute: Attribute Range 1. symboling: -3, -2, -1, 0, 1, 2, 3. 2. normalized-losses: continuous from 65 to 256. 3. make: alfa-romero, audi, bmw, chevrolet, dodge, honda, isuzu, jaguar, mazda, mercedes-benz, mercury, mitsubishi, nissan, peugot, plymouth,
archive.ics.uci.edu
- 해당 링크에서 다운로드
-> imports-85.data를 보면 칼럼명이 없음 - imports-85.names에 존재 -> 나중에 붙여주어야 함
?: missing count = 결측값

이러한 ?들을 string으로 인식할 수 있으므로 공백으로 바꿔준다
데이터 세트 등록
Azure > Data > Create

- 여기서 유의해야할 점은 첫번째 줄을 column 명으로 인식했다는 것이다
따라서, No headers로 변경하여 준다

데이터 수집/이해
디자이너 시작

데이터 이해
> Designer > Automobile_price_data 더블 클릭 > Ouputs > Preview

결측값이 있는 지 확인한다

데이터 준비
특성 이름 지정
> Designer > Edit Metadata
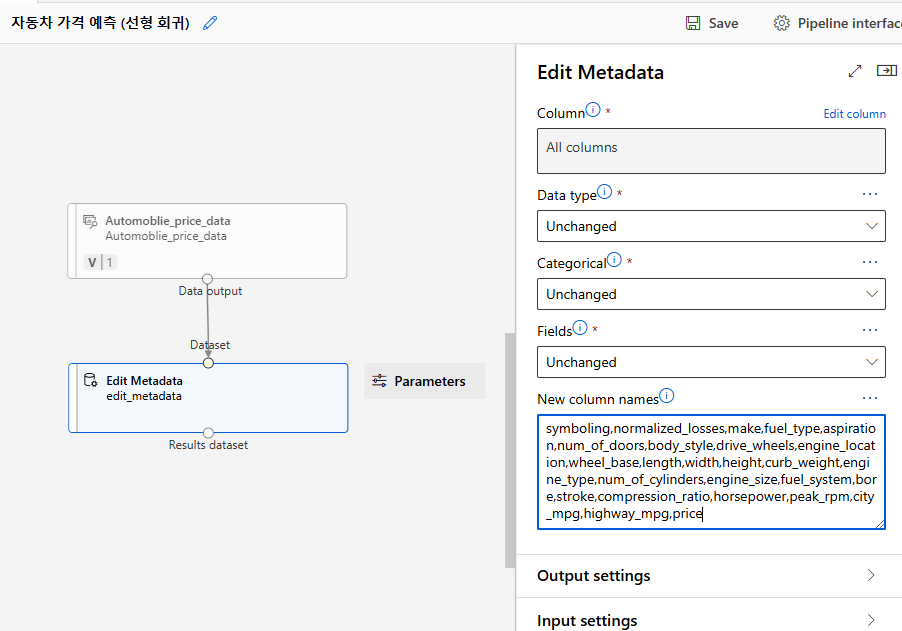
column 명이 없으므로 New column names에 직접 추가하여 준다
특성 선택
> Select Colmuns in Dataset

noramlized_losses 제외하고 모든 행 사용
누락값 처리
> Clean missing data
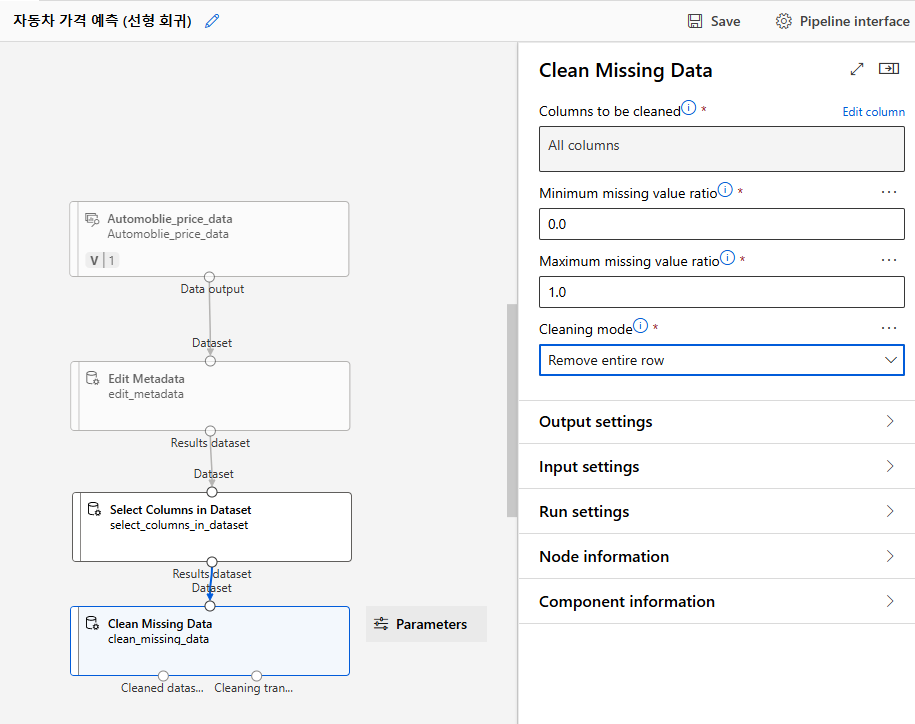
모든 행에 대하여 결측값이 있는 경우 Remove entire row로 처리
중간 점검 : 현재까지 작성 내용을 실행
Jobs > Clean Missing Data 우측클릭 > Preview Data > Cleaned data set

데이터 분리
> Designer > Split Data

전체 데이터를 학습 데이터 70%, 테스트 데이터 30%로 분리
학습 데이터는 Split Data 컴포넌트의 왼쪽, 테스트 데이터는 오른쪽 링크
모델링/평가
모델링 알고리즘 선택
회귀:수치예측
> Linear Regression

모델 학습(훈련)
앞 단계에서 생성한 모델 및 데이터를 각각 선으로 연결

모델 훈련을 위해 1) 학습 데이터세트 및 2) 어떤 알고리즘을 적용할 지 여부가 필요
알고리즘과 Split Data의 좌측 (학습 데이터) 데이터세트를 입력 값으로 적용
모델 테스트
> Score Model
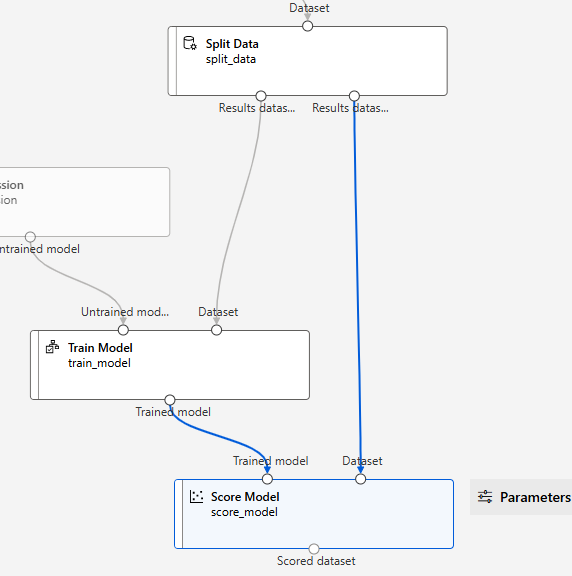
모델 테스트를 위해 1) 테스트 데이터세트 및 2) 훈련된 모델이 필요
Split Data의 우측 (테스트 데이터)과 훈련이 끝난 Trained Model을 입력 값으로 적용
모델 평가
> Evaluate Model

결과 확인
Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

추가 실습
최소제곱법과 경사하강법 비교
비교 대상
선형회귀 알고리즘의 Solution method를 달리하여 결과를 비교하고자 함
알고리즘 선택
새로운 Linear Regression 컴포넌트를 캔버스로 이동 (설정값은 그대로 사용)
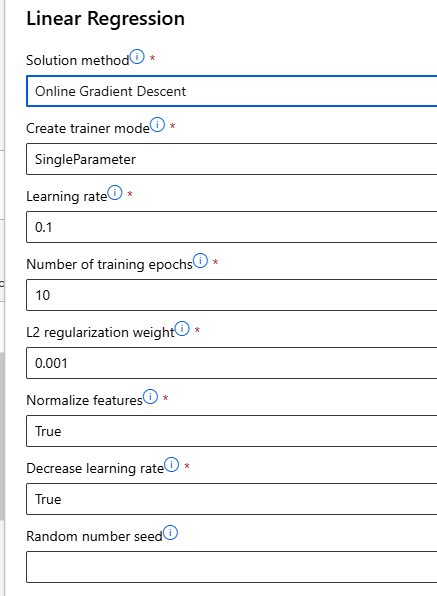
경사하강법(Gradient Desent)로 변경
Train Model과 Score Model는 기존의 것을 복사 붙여넣기
-> Evaluate Model과 연결

최종 구조는 위와 같다
결과 확인
Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

MAE: 직관적으로 "평균적으로 예측이 얼마나 벗어났는지"를 보여줌 - 평균적인 오차 크기를 직관적으로 평가
RMSE: 큰 오차를 강조하며 모델 평가 시 더 민감.
RSE: 모델이 데이터의 실제 값을 얼마나 잘 예측했는지를 나타내는 지표입니다
- 데이터의 실제 값과 예측 값 간의 차이를 측정
- 잔차의 표준편
- 작을수록 모델이 데이터를 잘 설명
RAE: MAE(Mean Absolute Error)를 기준으로, 모델의 성능을 평균 값(또는 기준 모델)과 비교하는 지표
- 값이 1보다 작으면 모델이 실제 값의 평균보다 더 나은 예측을 한다는 의미
- 값이 클수록 모델의 성능이 나쁨
Coefficient of Determination (R^2): 회귀 모델이 종속 변수의 분산을 얼마나 설명하는지를 나타내는 지표
- 값은 0에서 1 사이이며, 1에 가까울수록 모델이 데이터를 잘 설명
추가 실습
중요도 높은 변수 확인
Designer > Clone > 이름 변경
경사하강법 적용 컴포넌트 삭제

Train Model > True로 변경
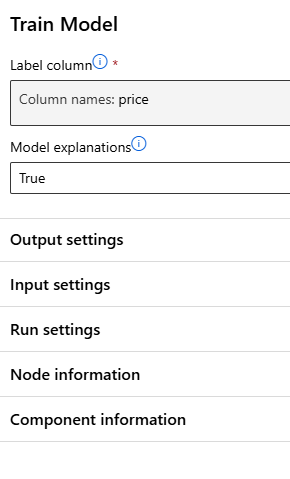
특성 중요도 - Permutation Feature Importance
> Permutation Feature Importance 추가
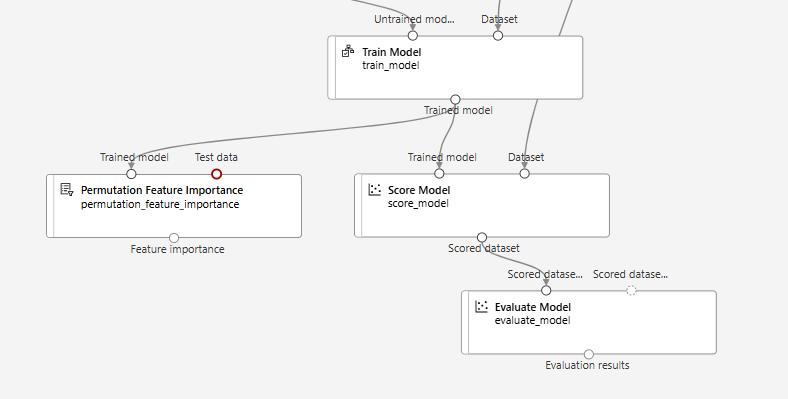
column 데이터를 섞음 -> 전체 성능에 영향 -> 중요한 칼럼으로 판단-
- 칼럼 별로 칼럼 내에서 섞는 것
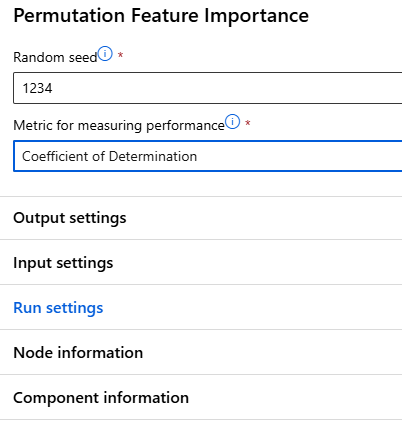
랜덤으로 섞을 수 있는 seed와 Metric을 정해준다
Split data component의 results dataset(예측 데이터)와 연결

결과 확인
Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

Jobs > Permutation Feature Importance 우측버튼 클릭 > Preview data > Feature importance
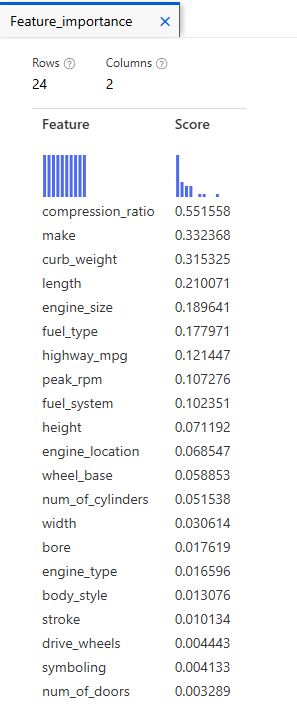
숫자가 클수록 중요한 변수임을 알 수 있음
-> 압축비가 높은 차량은 보통 고성능 차량이나 효율적인 엔진을 사용하는 차량에 해당
가장 높은 비율의 1/2까지 주요한 요소로 생각하는 경우가 많음
Train Model 더블 클릭 > Explanation
PFI 변수 중심
AFI 모델 학습 중심 - 이번 학습에 어느 변수를 더 중요하게 봤는가
-> 겹치는 변수는 중요한 변수이다
- 중요한 변수로 다시 분석
engine_size, length, width, compression_ratio, make, fuel_type, prcie, bore, curb_weight
결과 확인

MS Azure ML Designer를 활용한 군집 모델
K-means 알고리즘을 이용한 펭귄 데이터 군집화 모델 구현
배경 및 모델링 목표
Palmer Penguins 데이터 세트를 분석하여 펭귄들을 군집화할 수 있는 모델 구현
- 통계학 및 데이터과학 교육용으로 널리 사용되는 데이터세트
- 2007~2009년 남극의 Palmer 군도에서 수집된 펭귄 데이터로 구성
Palmer Penguins 데이터 세트의 특성들을 통해 펭귄 샘플들을 군집화
알고리즘
- K-means 군집 알고리즘
데이터 수집
UCI Machine Learning Repository에 접속하여 Palmer Penguins 데이터 세트 얻을 수 있음
Palmer Penguins - UCI Machine Learning Repository
UCI Machine Learning Repository
The data was collected for research that was conducted as part of the Palmer Station, Antarctica, Long-Term Ecological Research program which was supported by grants through the National Science Foundation, Office of Polar Programs (NSF-OPP). Please see th
archive.ics.uci.edu
> Dataset Home Page
를 클릭하면 아래 웹사이트가 나온다
palmerpenguins R data package • palmerpenguins
palmerpenguins R data package
Data for three penguin species observed in the Palmer Archipelago, Antarctica, collected by Dr. Kristen Gorman with Palmer Station LTER. A great intro dataset for data science teaching and learning, and a useful replacement for the iris dataset.
allisonhorst.github.io
> Browse Source code > inst > extdata > penguins.csv 다운로드
-> NA로 되어 있는 결측값 공백으로 변경
데이터 세트 등록
Azure > Data > Create하여 등록
데이터세트 가져오기
Designer > Create > Penguin 데이터 드래그앤 드롭
데이터 이해
더블 클릭 > Output > Preview 확인
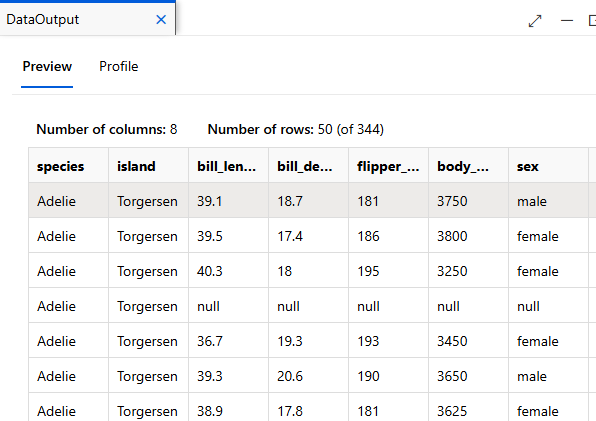
-> species는 train clustering model에서 사용하지 않음: 수치로 군집을 분류할 예정
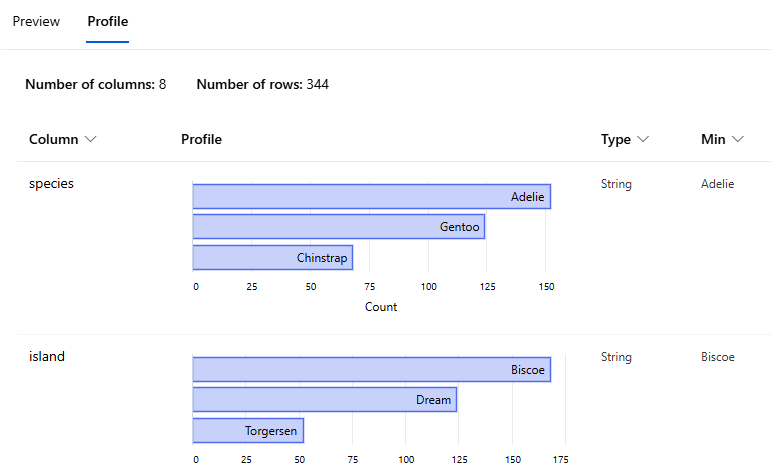
이를 참조하여 제일 인원이 많은 군집이 Adelie 종임을 짐작할 수 있음
String Type : species, island, sex
Execute Python Script 컴포넌트를 이용하여 산점도를 확인한 후, 군집화에 적합한 데이터인지 여부 확인

데이터 준비
특성 선택
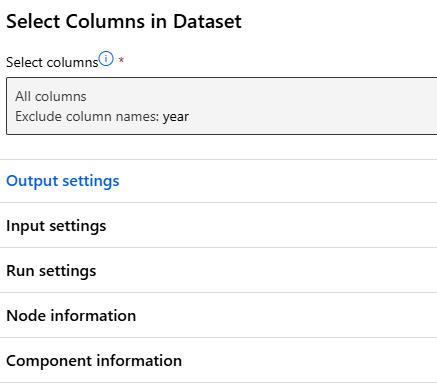
- year 제외 모든 열 선택
누락값 처리
Clean Missing Data Component
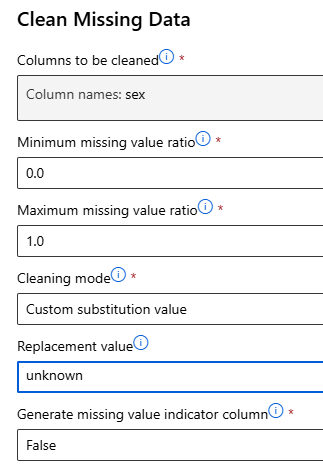
누락값 처리 – 수치형 데이터 (선택 1 : 전체 행 삭제)
누락값 처리 – 수치형 데이터 (선택 2 : 평균값으로 변환)
-> 2번으로 진행
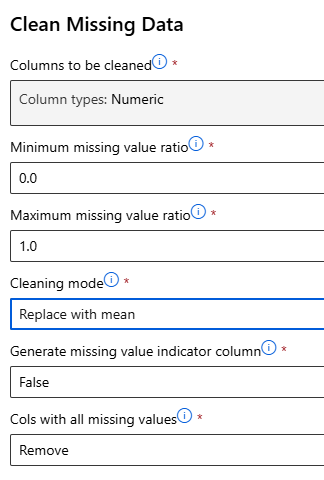
데이터 변환
String → Category(범주)
Edit Metadata 이용

Category→ Indicator value
Convert to Indicator values 이용

정규화
- 수치형 데이터 정규화
Normalize Data 이용
Transformation method를 MinMax로 지정
Columns to transform > Edit column >Column types를 수치형 데이터로 지정
- Min-Max 정규화: 데이터를 0과 1 사이의 값으로 변환
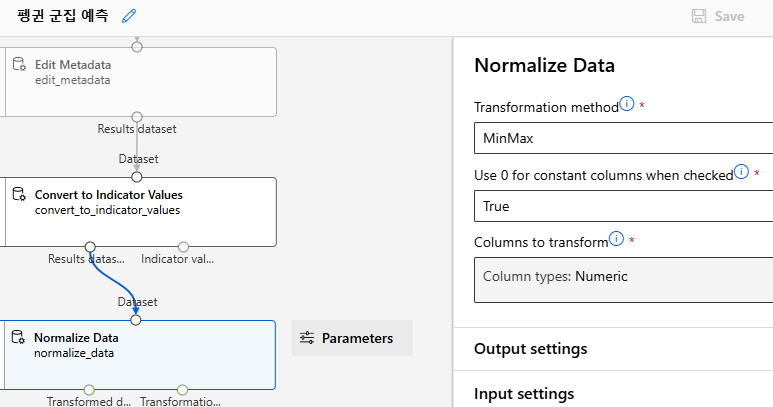
중간 점검: 현재까지 작성 내용을 실행
Configure & Submit
Jobs > Execute Python Script 더블 클릭 > Outputs + logs > graphics/scatterplot.png
python으로 그린 산점도를 확인하면 다음과 같다

Jobs > Normalized Data > Preview data > Transformed dataset
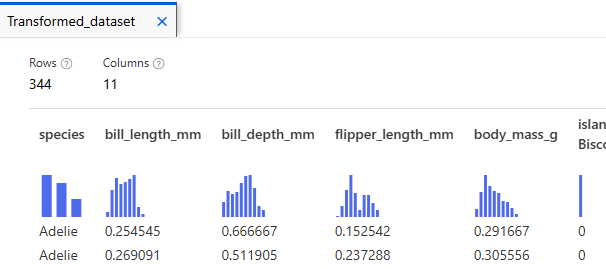
지금까지의 데이터 정리 작업이 적용된 결과 표시
데이터 분리
Designer > Split Data
앞 단계의 datasets를 입력 값 사용, 데이터 분리 컴포넌트에 선으로 연결

모델링/평가
모델링 알고리즘 선택
- K-means Clustering
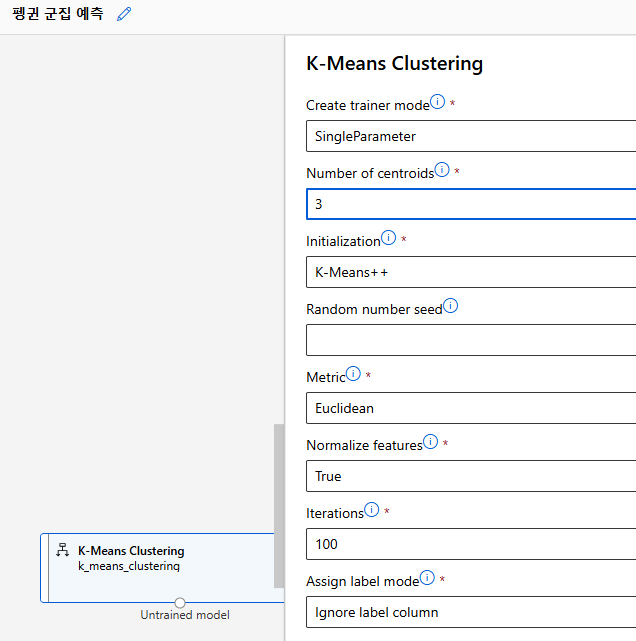
모델 학습(훈련)
군집화에 사용될 컬럼을 지정

모델 테스트
Assign Data to Cluster
테스트 결과를 산출
컴생성한 훈련 모델 및 테스트 데이터를 각각 선으로 연결하여 입력 값으로 사용

모델 평가
Evaluate Model
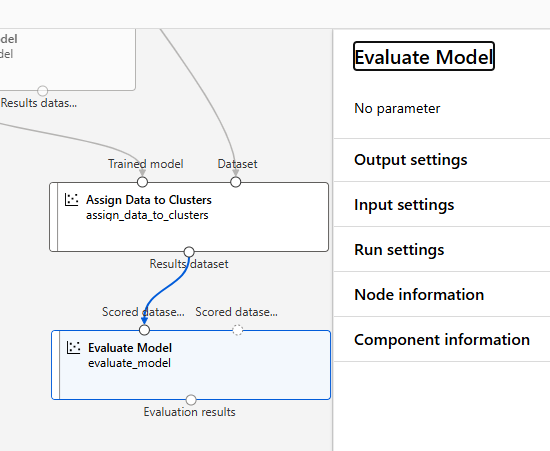
결과 확인
Configure & Submit
Jobs > Assign Data to Clusters 우측버튼 클릭 > Preview data > Results Dataset
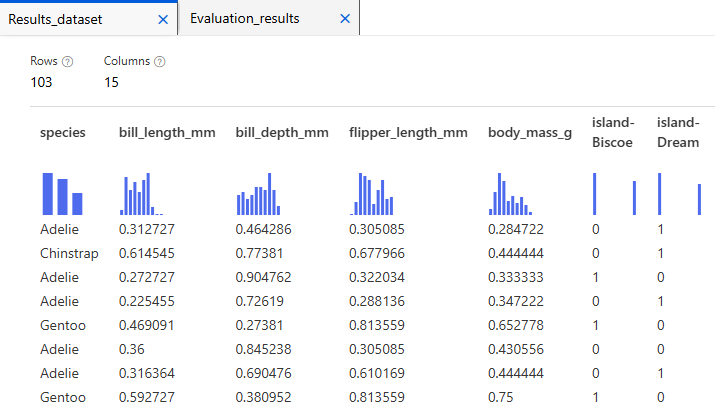

종별로 구분이 잘되었는 지 확인
- test 데이터를 넣었을 때 어떤 군집으로 분리되었는 지 species에 있는 정보와 비교하여 정확도를 보면됨
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

추가 실습 – 유추 파이프라인
웹 서비스 배포를 위한 과정, 배포 전 테스트
Jobs > Create inference pipeline > Real-time inference pipeline
- 유추 Pipeline 구성을 위해 각 단계에 컴포넌트들이 자동으로 추가/삭제 됨

TD - transform을, 전처리를 위한 데이터
MD - model을 위한 데이터
- 최종적으로 assign 만 하면 되는 것으로 판단
필요 없는 component 삭제

web service input 추가

enter data manually 추가

Configure & Submit
유추 파이프라인 테스트
Assign Data to Clusters > Preview data > Results dataset
유추 파이프라인 배포
Deploy 클릭
Endpoint 이름 및 Compute 유형을 선택 후 Deploy
엔드포인트 : 통신 채널의 한 쪽 끝 지점을 의미
엔드포인트에서 머신 러닝 모델로의 인증, 접근 권한, 부하 분산 등 관리 가능
Endpoints에서 확인 가능
Consume에서 REST endpoint 확인 가능

MS Azure ML Designer를 활용한 분류 모델
Boosting 알고리즘을 이용한 개인 수입 예측 모델 구현
실습 개요
미국의 인구조사(census) 데이터를 분석하여 개인의 연간 소득을 예측할 수 있는 모델 구현 이진 분류 모델을 통해 연간 소득 5만 달러를 기준으로 개인을 구분하고자 함
알고리즘
앙상블 기법
: Base Learner(Weak Learner) -> Metal Learner
- Weak learner를 이용하여 Strong learner를 구성하는 효과적인 방법
- 앙상블의 대표적 기법들은 Bagging과 Boosting으로 구분
Bosting: 점진적으로 발전시킴 - sequential -> 누적 학
Bagging: 각 데이터가 생긴 것이 다름- Parallel
-> 일반적으로 Boosting 기법이 성능이 더 좋
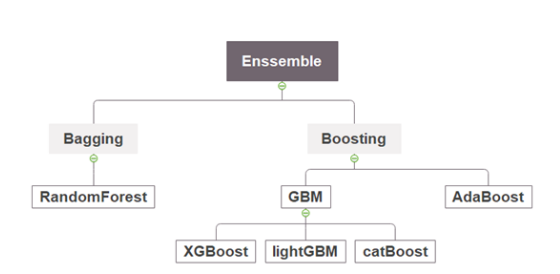
부스팅
부스팅은 여러 개의 단순한 모델(weak learner)을 순차적으로 구성하는 앙상블 모델의 일종 하나의 깊은 트리로 구성하는 랜덤 포리스트와 달리 2-깊이 나무를 여러개 이용하여 Strong learner 구축
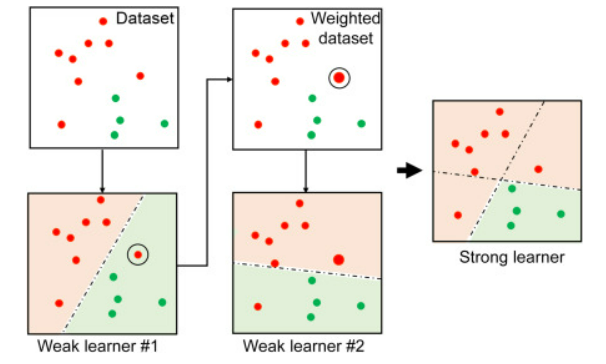
AdaBoosting은, 각 단계에서 이전 단계의 단점을 개선해 나가는 부스팅 알고리즘의 일종으로, 큰 오류에 집중하여 개선하는 방법을 취함
- weak learner로 깊은 Tree가 아닌, 깊이가 2인 stump를 사용
- 깊은 Tree에 비해 예측력이 낮은 여러 stump들의 가중치를 달리하여, 예측력 높은 모델을 구성함
- Root에 제일 가까운 곳을 stump라 함
데이터 세트
adult_census.csv
데이터 준비
특성 선택
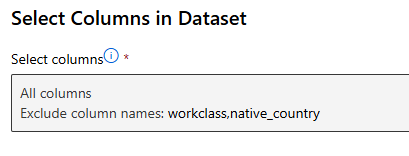
workclass, native_country 제외 선택
누락값 처리
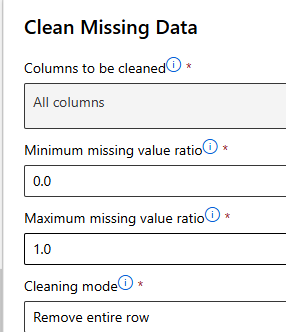
데이터 변환
String → Category → Indicator value
String → Category
Edit Meta Data

Category→ Indicator value

중간 점검
Configure & Submit
Jobs > Convert to Indicator Values 우측버튼 클릭 > Preview data > Results Dataset

데이터 분리
Designer > Split Data
전체 데이터를 학습 데이터 70%, 테스트 데이터 30%로 분리
학습 데이터는 Split Data 컴포넌트의 왼쪽, 테스트 데이터는 오른쪽 링크
모델링/평가
모델링 알고리즘 선택
Two-Class Boosted Decision Tree
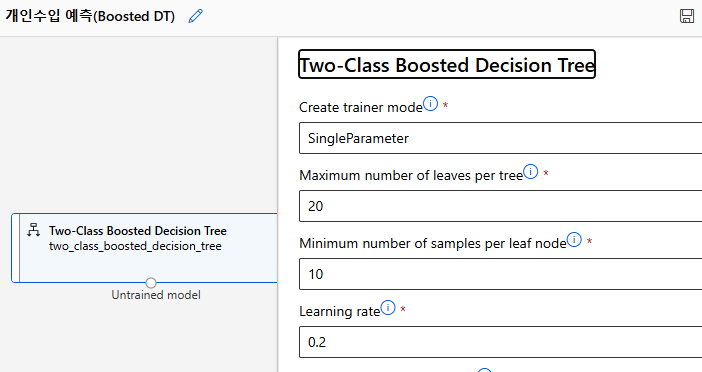
Tune Model Hyperparameters Component
머신 러닝 알고리즘 및 Split Data Component의 학습 데이터와 연결


- 다양한 하이퍼파라미터 값을 조합해 실험하고, 성능이 가장 좋은 설정을 선택
하이퍼파라미터(Hyperparameters): 머신러닝 모델의 학습 과정에서 사용자가 미리 설정해야 하는 값
결과 확인
Jobs > Tune Model Hyperparameters Component > Preview data > Sweep results

-> 첫 번째 결과로 알고리즘 하이퍼파라미터 사용
Designer > Two-Class Boosted Decision Tree > 알고리즘의 하이퍼파라미터 설정
-> 위의 결과 반영

모델 학습(훈련)

70%의 학습 데이터와 모델으로 학습
모델 테스트

30%의 test 데이터와 train model으로 모델 테스트
모델 평가
결과 확인
Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluated results

MS Azure ML Designer를 활용한 개인 실습
의료비 데이터
Medical Cost Personal Datasets 를 분석하여 개인 의료비를 예측할 수 있는 회귀 모델 구현
데이터 세트
아래의 링크에서 다운로드
https://www.kaggle.com/datasets/mirichoi0218/insurance
Medical Cost Personal Datasets
Insurance Forecast by using Linear Regression
www.kaggle.com
개인 실습 결과
- Region 칼럼 제외하고 진행
- Gradient Descent 알고리즘 사용


- Least Squares와 결과 지표를 비교 해보았다
Least Squares: 오차(잔차)의 제곱 합을 최소화하여 가장 적합한 모델 파라미터를 찾음

오늘의 간단한 후기
실습 내용이 너무 많고 빨라서 따라가는 것이 힘들었다. 그래도 여러 가지 실습을 해보고 마지막에 개인 실습까지 완성할 수 있어서 좋았다
절차는 대부분 데이터 셋 불러오기 -> 사용할 칼럼 선정 -> 누락값 처리 -> string 데이터가 있으면(string -> categorical -> Indicator) -> 데이터 나누기(학습/테스트) -> 모델 선정 -> 모델 훈련 -> score model -> evaluate model로 성능 평가 인 것 같았다
여기에서 어떤 칼럼을 사용할 지 모르겠으면 heatmap을 쓰거나 PFI, AFI를 사용하는 것 같다.
PFI는 test data랑 train model을 사용한다
출처
[1] UCI Machine Learning Repository, "Adult Census Income Dataset," *Kaggle*. [Online]. Available: https://www.kaggle.com/datasets/uciml/adult-census-income. [Accessed: Jan. 20, 2025].
[2] UCI Machine Learning Repository, "Adult Dataset," *UCI Machine Learning Repository*. [Online]. Available: https://archive.ics.uci.edu/dataset/2/adult. [Accessed: Jan. 20, 2025].
[3] UCI Machine Learning Repository, "Automobile Dataset," *UCI Machine Learning Repository*. [Online]. Available: https://archive.ics.uci.edu/dataset/10/automobile. [Accessed: Jan. 20, 2025].
[4] UCI Machine Learning Repository, "Palmer Penguins Dataset," *UCI Machine Learning Repository*. [Online]. Available: https://archive.ics.uci.edu/dataset/690/palmer+penguins-3. [Accessed: Jan. 20, 2025].
[5] A. Horst, "Palmer Penguins," *Palmer Penguins Project*. [Online]. Available: https://allisonhorst.github.io/palmerpenguins/. [Accessed: Jan. 20, 2025].
[6] Bommbom, "Boosting 알고리즘: AdaBoost, GBM, XGBoost, LightGBM, CatBoost," *Bommbom's Tech Blog*. [Online]. Available: https://bommbom.tistory.com/entry/Boosting-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98AdaBoost-GBM-XGBoost-LightGBM-CatBoost. [Accessed: Jan. 20, 2025].
[7] ScienceDirect, "AdaBoost," [Online]. Available: https://www.sciencedirect.com/topics/engineering/adaboost. [Accessed: Jan. 20, 2025].
[8] M. Choi, "Insurance Dataset," [Online]. Available: https://www.kaggle.com/datasets/mirichoi0218/insurance. [Accessed: Jan. 20, 2025].
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(강명호 강사님)을 기반으로 제작되었습니다
깃허브 소스코드의 내용을 담고 있습니다
Microsoft에서 제공하는 Dataset을 포함하고 있습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다



