

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- msai
- 마이크로소프트 ai 스클
- microsoft ai school
- 마이크로소프트
- 마이크로소프트 ai 스쿨 6기
- 마이크로소프트 AI
- micsrosoft ai
- 마이크로소프트 ai school 6기
- microsoft ai school 6기
- MS
- microsoft
- 마이크로소프트 ai 스쿨
- microsoft ai
- Today
- Total
연랩
[Microsoft AI School 6기] 1/21(24일차) 정리 - MLD, 분류 모델, 회귀모델 본문
[Microsoft AI School 6기] 1/21(24일차) 정리 - MLD, 분류 모델, 회귀모델
parkjiyon7 2025. 1. 21. 18:41MS Azure ML Designer를 활용한 회귀 모델
트리기반 알고리즘을 이용한 자동차 가격 예측 모델 구현
Azure 제공 회귀 알고리즘
Poisson Regression
- 푸아송 분포를 이용하여 만든 회귀 알고리즘
- 푸아송 분포 : 단위 시간 내에 특정 사건이 몇회 발생할 것인지를 나타내는 이산 확률 분포
- 단위 시간 당 특정 사건이 발생할 횟수를 예측함 (양의 정숫값) 예시 : 일주일 고객센터 문의 수, 하루 교통사고 발생 건수 예측
Linear Regression
- 선형회귀식을 이용하여 예측하는 회귀 알고리즘
- 독립변수(feature)와 종속변수(label)와의 선형적인 관계 예측
- 통계적 기법을 활용하며, 복잡하지 않은 선형 관계를 가질때 유용함
Bayesian Linear Regression
- 기존의 linear regression과 베이즈 확률 이론을 함께 사용하는 알고리즘
- 베이즈 확률 : 특정 사건의 발생 확률은 이전에 일어난 사건에 영향을 받는다는 이론
- 데이터 간 연관관계가 충분히 나타나 있을 때 사용하면 빠른 모델링이 가능함
Neural Network Regression
- 인공신경망을 활용한 회귀 알고리즘
- 선형 회귀로 모델링하기 어려운 복잡한 문제에 적용
- 인공신경명 모델 특성 상 모델링에 시간이 많이 걸림
Decision Forest Regression
- 의사결정나무 알고리즘을 이용한 회귀 알고리즘
- 메모리 효율적인 알고리즘으로 높은 성능을 보임
Boosted Decision Tree Regression
- 의사결정나무 기반 회귀 알고리즘
- 결정나무를 순차적으로 강화하여 학습하는 모델
- 단순 의사결정나무 회귀 알고리즘에 비해 메모리 사용량이 높지만 정확도는 향상됨
Fast Forest Quantile Regression
- 의사결정나무를 이용하여 범위나 분포를 예측하는 회귀 알고리즘
- 1/4 , 2/4, 3/4 등 사분위수 위치의 값을 빠르게 예측
- 예시 : 가격, 온도 등의 분포를 예측할 때 주로 사용됨
알고리즘
-회귀 나무 (Regression Tree)
CART (Classification And Regression Tree)
- 분류 문제와 회귀 문제에 모두 사용될 수 있는 나무(Tree) 기반 알고리즘
- 범주 예측과 수치 예측 모두에 사용 가능함을 의미함
- 회귀에 사용될 경우 불순도(gini index)가 아닌 실측값과 예측값의 오차를 이용함
의사결정나무 회귀
- 의사결정나무 알고리즘을 회귀 분석에 적용 한모델
- 입력변수의 영역을 여러 구간으로 나누고, 각 구간에 대해 고정된 값을 예측하는 방식으로 동작
- 이를 통해 비선형적인 데이터에 대해서도 유연한 예측 가능
구획 -> 구간의 평균
나무의 노드 :
- 루트노드 : 전체 데이터 세트를 포함하는 최상위 노드
- 내부노드 : 특정 기준에 따라 데이터를 두 개의 하위 노드로 나누는 노드
- 리프노드 : 더 이상 나눌 수 없는 최종 노드. 노드의 값이 예측 값이 됨
분할 기준
- 각 노드에서 최적의 분할 기준을 찾기 위해 손실함수 사용
- 손실함수(MSE, MAE 등)를 최소화 하는 분할 선택
- MSE(평균제곱오차)가 일반적으로 사용되며, 각 분할된 구간 내의 데이터 포인트와 평균 간의 오차를 계산하여 최소화 하는 방향으로 분할 수행
의사결정나무 회귀 예시
- 데이터 분할 예시 (섭취량 10%일때)
- 모든 데이터에 대해 각 데이터 포인트들을 각 지역 평균과의 차이를 통해 RSS 계산

- 여기서 부터 계산하여 RSS 값을 구함
- 모든 데이터에 대해 각 데이터 포인트들을 각 지역 평균과의 차이를 통해 RSS 계산
- 최소의 RSS를 갖는 변수값을 기준으로 산점도를 분할 후 트리의 노드 생성

- 여기서는 70%가 최소 이므로 70을 루트로 설정

Boosted Decision Tree Regression vs Decision Forest Regression

실습
UCI Repository의 Automobile 데이터세트 이용
Designer >
데이터 세트 가져오기
칼럼 이름 부여: edit Meta Data
칼럼 선택: Select Columns in Dataset
누락값 처리: Clean Missing Data
여기까지 한 결과는 다음과 같다

Split Data로 70%를 학습 데이터
30%를 테스트 데이터로 사용
알고리즘: Boosted Decision Tree Regression, Decision Forest Regression
성능 비교

이후,
모델 학습: Train Model
- Label Column: price
모델 테스트: score Model
모델 평가: evaluate model
전체 구조는 다음과 같다

이를 실행 시킨 결과는 다음과 같다

추가 실습
linear regression 추가

Evaluation Model은 비교가 두개 까지 밖에 안되기 때문에
component 하나를 추가하고 add rows 추가
Execute Python Script 추가하여 수행

그냥 출력하면 비교 시 어떤 알고리즘인지 파악이 어려우므로 해당하는 행의 이름(알고리즘 이름) 추가
RAE, RSE 등의 필요 없는 요소는 select columns로 제거

구조는 다음과 같다

결과는 다음과 같다

MS Azure ML Designer를 활용한 분류 모델
신용 위험 예측 모델 구현
알고리즘
SVM (Support Vector Machine)
데이터를 두 개의 클래스 또는 여러 클래스 중 하나로 나누는 최적의 초평면(hyperplane)을 찾는 알고리즘
목표 : 두 클래스 간의 경계 정의
초평면 : 데이터를 나누는 경계 (2차원 공간에서는 선, 3차원 공간에서는 평면)
지원 벡터(Support Vector) : 각 클래스에서 경계에 가장 가까운 데이터 포인트들
마진(Margin) : 두 클래스 간의 거리 (마진을 최대화하는 것이 SVM의 목표)
- 마진이 클수록 모델의 일반화 능력 높음
아웃라이어의 허용 여부
하드 마진
- 데이터가 완벽하게 분리 되도록 함
- 모든 데이터 포인트가 초평면으로부터 일정 거리 이상 떨어져 있어야 함
- 마진의 폭이 줄어들 수 있으며, 과적합 문제 야기 가능
소프트 마진:
- 일부 데이터 포인트가 초평면에 가까이 있거나 초평면을 넘을 수 있음
- 실제 데이터는 완벽하게 분리되지 않는 경우가 많기 때문에 소프트 마진이 실용적
- 마진이 커지는 반면, 과소적합 문제 우려.
SVM에서는 규제 파라미터 (C) 를 활용, 마진 폭(하드마진, 소프트마진)을 조절하여 과대적합을 줄임
참고 : 𝐶 = 1/람다
커널 트릭
직선으로 구분할 수 없는 데이터 세트의 경우에 사용되는 변환 방법
비선형 데이터의 처리 :
- 데이터가 선형적으로 구분되지 않는 경우, SVM은 커널 트릭을 사용하여 데이터를 고차원 공간으로 변환하고, 변환된 공간에서 데이터를 선형적으로 분리
차원을 변경하여 구분할 수 있는 선 만들기


정규화
Min-Max 정규화
정의 : 데이터를 0과 1사이로 변환하는 정규화 방법
장점 : 알고리즘이 특정 속성에 대해 편향되지 않도록 함
단점 : 이상치에 매우 민감함 (이상치가 있으면 데이터 범위가 왜곡될 수 있음)
Max Abs 정규화
정의 : 데이터의 절대 최대값을 기준으로, 데이터를 (-1~1)의 범위로 변환하는 방법
장점 : 데이터의 중심을 유지하면서 크기만 조정할 수 있음
- 양수와 음수가 섞여 있는 데이터에 유용함
단점 : 절댓값 최대치에 민감 (여전히 이상치가 문제될 수 있음)
tanh 정규화
정의 : 하이퍼볼릭 탄젠트(tanh) 함수를 이용하여 데이터를 정규화 하는 방법
적용 : 데이터 표준화 후 tanh 함수를 적용하여 값을 [-1, 1] 범위로 변환
장점 :
- 데이터의 분포가 중간값을 중심으로 대칭적이지 않을 때 유용
- 이상치의 영향을 적게 받음
단점 : 계산이 상대적으로 복잡함
비용 민감 학습
UCI의 German credit card 데이터의 경우, 위험도가 나쁜 경우를 과소평가 하는 것은 더 큰 위험을 초래할 수 있음을 고려해야 함
ex) 저 위험군의 사람을 고위험군으로 분리 : cost가 2
고 위험군의 사람을 저 위험군으로 분리: cost가 5

비용이 민감한(cost-sensitive) 상황에서 데이터 간의 불균형을 해소하기 위한 데이터 전처리가 필요함
비용 민감 학습 (Cost-Sensitive Learning) : 잘못된 예측의 비용(Cost)이 동일하지 않을때 사용함. 복제 등과 같은 방법으로 비용에 민감한 데이터의 비중을 높여서, 모델이 더 신중하게 예측하도록 조정함
샘플링 기법 (Sampling Techniques) : 데이터 불균형 문제를 해결하기 위한 방법으로, 소수의 클래스의 데이터를 오버샘플링하여 소수 클래스에 대한 예측 성능을 향상시킴
비용 민감 로지스틱 회귀 (Cost-Sensitive Logistic Regression) : 로지스틱 회귀 모델을 이용하여 클래스 별 다른 가중치를 부여하는 방식
임계값 이동 (Threshold Moving) : 예측의 임계값을 조정하여 고위험 클래스를 더 쉽게 예측할 수 있도록 함
-> 실습에서는 비용 민감 학습 이용 에정
실습
데이터 수집
UCI의 German Credit Data 데이터세트 이용
아래의 링크에서 다운로드 가능
https://archive.ics.uci.edu/dataset/144/statlog+german+credit+data
UCI Machine Learning Repository
This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license. This allows for the sharing and adaptation of the datasets for any purpose, provided that the appropriate credit is given.
archive.ics.uci.edu
데이터 세트 등록
Azure > data
- 칼럼명이 없으므로 No headers로 등록
머신러닝 디자이너 시작, 데이터 세트 가져오기
> Designer
데이터 세트 등록
내용 확인

데이터 준비
메타 데이터 변환
- 칼럼명 부여
> Edit Meta data

데이터 변환
String→Category
> Edit Metadata

Category→Indicator value
> Convert to Indicator Values

데이터 분리
> Designer > Split data

70% 학습 데이터, 30% 테스트 데이터로 분리
실험 설계

데이터 변환 - 위험도 고려 및 정규화
> Execute Python Script

- 파이썬 코드로 비용 민감 학습
-> component가 없음
저위험: 1, 고위험: 2
고위험을 5배 증
정규화
Normalize Data
- Tanh 정규화 사용

마찬가지로 다른 곳에도 수행
학습 데이터 -> 비용 민감학습 -> 정규화
학습데이터 -> 정규화
테스트데이터 -> 비용민감학습->정규화
테스트 데이터->정규화

모델링 알고리즘 선택
SVM, Two-class Decision Tree

모델 훈련(학습)

모델 테스트

다른 노드에도 마찬가지로 다 해주면 다음과 같다

모델 평가
Evaluate Model
- SVM, Tree의 모델들을 추합하여 평가

중간결과 확인
save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results
- 양성을 잘 걸러내는 것이 중요
결과 확인 -SVM

결과 확인 - Two-class Boosted Decision Tree

취합/결과 확인
SVM, Tree의 Evaluate Model 결함
> Add Rows
> Execute Python Script(Add Rows와 연결)
row 이름
ex) SVM , 비용민감 처리(가중치) 여부 표

파이썬 코드는 다음과 같다

> Select Columns in Dataset
Evaluate Model의 열 중 원하는 것 선택

결과 확인
save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

정밀도(Precision):
모델이 양성으로 예측한 것 중 실제로 양성인 비율: TP/TP+FP
재현율(Recall):
실제로 양성인 것 중 모델이 양성으로 예측한 비율: TP/TP+FN
MS Azure ML Designer를 활용한 분류 모델
특성 선택 기법을 활용한 개인 수입 예측 모델 구현
알고리즘
2-Class Boosted Decision Tree
Garbage in Garbage out
쓰레기 데이터가 많으면 쓰레기가 나온다.
Garbage data :
- 모델이 예측하는데 관련 없는 데이터 (예측값(Label)과 무관한 데이터)
- 비슷한 특성이 중복되는 데이터
필요한 특성(컬럼, 독립변수)만으로 모델 학습
- 필요한 특성들 만을 사용하여 모델링해야 올바른 예측 결과를 기대할 수 있음
- 모델의 빠른 학습과 성능 향상을 기대할 수 있음
- 처리할 데이터의 양이 축소되어, 최소의 리소스 사용이 가
특성 선택
- 특성 중 모델 학습에 가장 유용한 특성을 선택함
- 수집한 데이터에서 가장 좋은 성능을 보이는, 데이터의 부분집합을 찾아냄
종류 :
- Filter Methods
- Wrapper Methods
- Embedded Methods
Filter Methods
전처리 과정(모델 학습 이전 과정)에서 특성 선택
통계적 방법을 통해 각 특성들의 관련성을 계산하여 특성 선택
피어슨 상관분석, 카이제곱 검정 등을 방법으로 상관관계를 파악하여 선택함
카이제곱 분포 (Chi-Square Distribution)
- 정규 분포를 따르는 독립적인 변수들의 제곱의 합.
- 모집단의 분산을 추정할 때 주로 사용됨
카이제곱 검정(Chi-square test) :
- 범주형 데이터에서 기대 빈도와 관찰된 빈도 간의 차이를 확인할 때 사용
- 두 범주형 데이터에서 변수 간 독립성 여부를 검정할 때 사용
Wrapper Methods
모델 학습 및 검증을 반복하여 특성 선택
특성들의 다양한 조합으로 모델의 학습을 진행하며, 성능 지표를 바탕으로 특성 조합 구성
최적의 특성 조합을 찾는 방법으로 Forward Selection, Backward Elimination 등이 있음
Embedded Methods
모델 자체에 포함된 특성 선택 기능을 이용하는 방법
학습 알고리즘 내에서 특성들의 영향력을 축소하는 방식으로 특성 선택
LASSO, Ridge 등의 기법이 대표적임Wrapper Methods
파이프라인 생성 -> 특성 선택
> Designer > 개인 수입 예측 > Clone
Split data까지 남기고 삭제
Filter-based Feature Selection
income 중심으로 다른 변수들이 얼마나 독립적인지 봄
Number of desired features: 몇 개의 변수가 종속적인지 봄
- 정답 레이블과의 종속성을 찾음
-> 독립 변수들끼리는 상관이 없어야 하나 정답과는 연관 관계 여야 함

모델링 알고리즘 선택
Two-Class Boosted Decision Forest
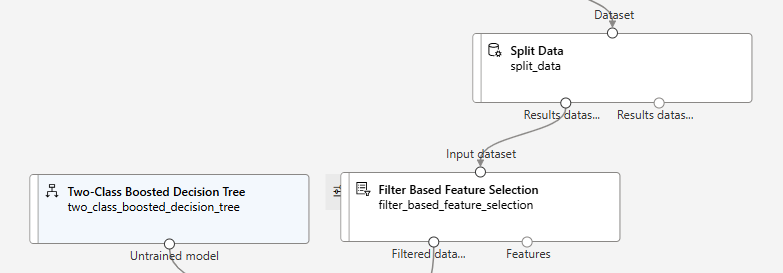
모델 훈련(학습)

모델 테스트

split data의 테스트를 그대로 쓰면 안된다
학습 데이터가 필터를 거쳐서 선정된 9 개의 컬럼으로만 훈련했기 때문이다
Filter Based Feature Selection에서 적용한 방식을 test에도 적용하여 똑같은 9개의 칼럼을 써야 함
즉, Filter로 걸러진 9개의 칼럼만을 test data에서도 사용하도록 해야 한다
> Select Columns Transform

- 칼럼 정보만 받아서 처리
- Tranform data를 정의만 하기 때문에
Apply transformation 추가
> Apply transformation

select 된 칼럼을 test 데이터에 apply 해준다
test를 위해 Score Model에 연결

모델 평가
> Evaluate Model

결과 확인
save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

Jobs > Filter Based Feature Selection 우측버튼 클릭 > Preview data > Features

어떤 요소를 반영 했는 지 확인 가능
MS Azure ML Designer를 활용한 분류 모델
고객 대출 자격 예측 모델 구현
알고리즘
로지스틱 회귀 알고리즘 (Logistic Regression)
-> 분류 알고리즘
로지스틱 회귀
종속 변수가 이진(0 또는 1)인 경우에 사용되는 회귀 분석 기법
ex) 환자의 질병 유무(있다/없다), 이메일의 스팸 여부(스팸/스팸아님)
0과 1로 되어 있는 데이터를 -> S자 곡선으로 변경

오즈비(Odds ration)
- 실패 대비 성공 확률의 비율
Odds = 이길 확률(p)/질 확률(1-p)
-> 그래프 분석 어렵
-> 로짓 변환

로짓 변환
Logit(p) = log(p/1-p)
- Odds 비에 log를 씌운것

- 이에 역함수를 취하면 우리가 원하는 S자 곡선의 형태를 얻을 수 있음
로짓변환의 역함수

- 이를 시드모이드 함수라고 부름
특성 : 출력값의 범위는 (0, 1)
- z 가 0일때 출력값은 0.5
- z 가 매우 큰 양수 : 출력값은 1에 가까움
- z 가 매우 큰 음수 : 출력값은 0에 가까움
z에 선형식을 대입 -> 계수를 찾는 것

샘플링 방법
층화 추출 (Stratified Sampling)
모집단을 여러 하위 집단(층)으로 나눈 다음 각 층에서 표본을 무작위로 추출
모집단이 이질적일 경우 특성을 더 잘 반영하기 위해 사용함
단순 무작위추출 (Simple Random Sampling)
모집단의 각 구성원이 동일한 확률로 표본으로 선택되는 방법
모든 구성원이 같은 확률로 선택되지만 모집단의 특정 특성이 고르게 반영되지 않을 수 있음 (모집단이 균질할 때 주로 사용

데이터 수집
아래의 링크에서 다운로드
https://www.kaggle.com/datasets/altruistdelhite04/loan-prediction-problem-dataset
Loan Prediction Problem Dataset
www.kaggle.com
실습
Azure > Data > train_loan.csv 등록i
Designer > 데이터 세트 드래그앤 드롭 > 더블 클릭 > Ouputs > Preview

데이터 준비
특성 선택
Select Columns in Dataset
- 사용할 칼럼 선정

누락값 처리
0으로 처리
- Credit_History
- LoanAmount
- Loan_Amount_Term
- Dependents

false 처리
Self_Employed, Married

unknown 처리
Gender

데이터 변환
Boolean→Category : Married, Self_Employed
> Edit metadata

String→Category : Gender, Dependents, Education, Property_Area

Integer→Category : Credit_History

Category→ Indicator value
> Convert to Indicator Values

CoapplicantIncome - interger 변수라서 Azure ML이 categorical 형식으로 인식하기 때문에 제외
데이터 분리
> Split Data

전체 데이터를 학습 데이터 70%, 테스트 데이터 30%로 분리
학습 데이터는 Split Data 컴포넌트의 왼쪽, 테스트 데이터는 오른쪽 링크
모델링/평가
모델링 알고리즘 선택
분류: 범주 예측
> Two-Class Logistic Regression

모델 학습(훈련)
분류 모델에서는 정답(라벨, Label)으로 사용할 컬럼을 지정

정답 칼럼: Loan_Status
모델 테스트
> Score Model

모델 평가
> Evaluate Model

결과 확인
save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

추가 실습 - 층화 추출
층화 추출을 통해 데이터 분리 시 샘플링 편향을 최소화하여 결과 비교
학습 데이터와 테스트 데이터로 분리 – 층화 추출
> Split Data
Convert to Indicator Value의 Results datasets를 입력 값 사용
- 층화 추출

층화 추출 기준: Loan_Status
모델 훈련 및 평가

결과 확인
save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

MS Azure ML Designer를 활용한 분류 모델
오버샘플링을 이용한 CRM 고객 이탈 예측 모델 구현
CRM: Customer relationship management
알고리즘
Boosted Decision Tree
오버샘플링 (Over Sampling)
불균형한 데이터 (Imbalanced data)
- 데이터세트의 각 클래스 간 데이터 수가 많이 차이나면, 학습된 모델의 성능에 좋지 않은 영향을 줌
- 분류 모델의 학습 데이터의 클래스 간 비율 차이가 큰 경우, 비율이 높은 쪽으로 분류 결과를 출력하는 경향 있음
오버샘플링 (Over Sampling)
불균형한 데이터세트에서 소수 클래스의 데이터를 증가시켜 클래스 간의 불균형을 조정하기 위해 사용되는 기법
랜덤 샘플링 (Random Oversampling)
소수 클래스의 기존 데이터를 무작위로 복제하여 샘플 수를 늘리는 방법
장점 : 소수 클래스의 샘플 수를 손쉽게 증가시킬 수 있음
단점 : 데이터의 다양성을 늘리지 않고 단순 복제하기 때문에 모델이 복제된 샘플에 과적합될 수 있음
SMOTE (Synthetic Minority Over-sampling Technique)
소수 클래스 샘플들을 이용하여 새로운 샘플을 합성하여 생성하는 방법
기존 샘플과 그 이웃 샘플들 간의 선형 결합을 통해 새로운 샘플을 만듦
장점 :
- 데이터 다양성을 증가시켜 과적합을 줄일 수 있음
- 소수 클래스의 분포를 더 자연스럽게 확장 가능
단점:
- 노이즈 데이터가 포함될 수 있습니다

-> 원래 데이터와 거리가 가까운 곳에 샘플을 늘림
동작 방식 :
- 같은 클래스에 속한 데이터 사이의 거리를, 랜덤한 값으로 내분하는 지점에 새로운 데이터 생성
- 임의의 데이터에서 동일한 클래스에 속한 데이터 중 가장 가까운 K 개의 데이터와의 선분 상에 새로운 데이터 생성

실습
데이터 수집
KDD Cup : Knowledge Discovery and Data mining competition
아래의 링크에서 데이터 수집 가능
SIGKDD : KDD Cup 2009 : Customer relationship prediction
SIGKDD : KDD Cup 2009 : Customer relationship prediction
Customer Relationship Management (CRM) is a key element of modern marketing strategies. The KDD Cup 2009 offers the opportunity to work on large marketing databases from the French Telecom company Orange to predict the propensity of customers to switch pro
www.kdd.org
> Data > 다운로드 가능
데이터 세트
이번 실습에서는 Azure에 내장되어 있는 데이터 이용
Azure > Designer > Component > Sample data -> 여러 가지 데이터 샘플들 관찰 가능
> CRM 검색 > CRM Dataset Shared, CRM Churn Labels Shared
- CRM Data Shared : 특성 데이터 (230개 컬럼)
- CRM Churn Labels Shared : 이탈 고객 레이블
- CRM Upselling Labels Shared :
- 새로운 서비스 잠재 고객 레이블
- CRM Appentency Labels Shared : 마케팅에 호의적인 고객 레이블
특성 데이터: 종속 변수 없는 독립 변수들
누락값 처리
0으로 채우기
> Clean Missing data

데이터 변환
열 병합
> Convert to Dataset

crm shared: 원래 데이터
crm_churn_labels_shared: 레이블 칼럼 - 1차원 데이터
- 차원이 다르면 문제가 생길 수 있기 때문에 형식을 맞춰주는 역할을 Convert to Dataset 컴포넌트가 수행
> Add columns
두 데이터셋을 연결
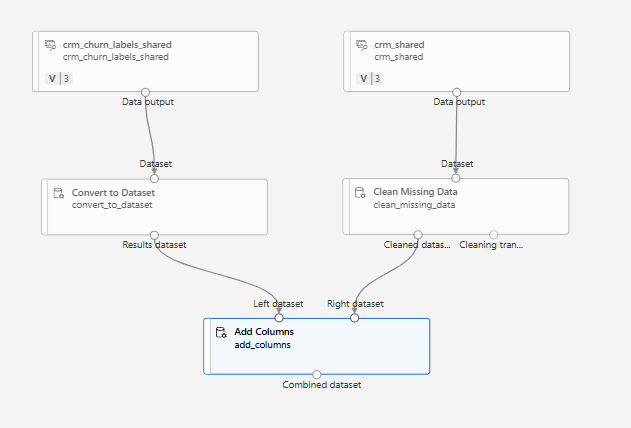
중간 결과 확인

누락값 처리

데이터 분리
> Split Data

모델링/평가
모델링 알고리즘 선택
> Two-Class Boosted Decision Tree

> SMOTE
오버샘플링을 위하여 SMOTE 사용

- SMOTE 컴포넌트의 설정창에서 Label column을 Col1 로 지정
모델 학습(훈련)
- 일반적인 데이터셋과 SMOTE로 오버 샘플링한 결과 비교

Lable column은 Col1

모델 테스트
- 테스트 데이터는 굳이 오버샘플링할 필요 없음
- 답만 맞추면 됨
> Score Model

모델 평가
> Evaluation Model

결과 확인
save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

결과가 별로 좋지 않음을 알 수 있음
- 0으로 많이 채워진 칼럼
- NaN이 많은 칼럼을 제거하는 것이 결과에 좋음
추가 실습 – 누락값 많은 데이터행/컬럼 제거
- 0으로 많이 채워진 칼럼
- NaN이 많은 행을 제거하는 것이 결과에 좋음
> Excute Puthon Script - Add Columns 컴포넌트와 연결


결과 확인

save > Configure & Submit
Jobs > Evaluate Model 우측버튼 클릭 > Preview data > Evaluation results

MS Azure ML Designer를 활용한 분류 모델
교차 검증을 이용한 개인 수입 예측 모델 구현
교차 검증
교차 검증(Cross Validation)은 학습 데이터 세트를 여러 부분으로 나누고 각 부분을 학습과 검증 용도로 번갈아 사용하여 모델을 학습 및 평가하는 방법을 의미함

K-Fold 교차 검증
전체 데이터세트를 K개의 폴드로 나누어 각 데이터 폴드를 학습 데이터와 검증 데이터로 번갈아 사용하여, 서로 다른 데이터로 학습한 실험들의 결과를 평균하여 학습 데이터와 모델을 평가하는 방법
K-Fold 교차 검증 결과를 통해 데이터 세트의 품질을 해석하고, 모델이 데이터의 변화에 영향을 받는지 여부 등을 파악할 수 있음
실습
> Designer > Clone > 개인수입 예측
Split data 전까지 지움
알고리즘
Two-Class decision Forest
교차 검증
> Cross Validate Model
-> Train Model의 상위 호환이라 생각

Label: income
결과 확인

save > Configure & Submit
Jobs > Cross Validate Model 우측버튼 클릭 > Preview data > Evaluation results by fold

추가 실습 (기존 방식과의 비교)
- Split Data 필요 없을 수 있음
아래와 같이 구조 변경

결과 확인
save > Configure & Submit
Jobs > Cross Validate Model 우측버튼 클릭 > Preview data > Evaluation results by fold

MS Azure ML Designer를 활용한 개인 실습
와인 데이터
- Wine Quality 데이터 세트를 분석하여 와인의 종류(white or red)를 분류하고, 와인의 특성을 통해 품질을 예측하는 모델 구현
포르투갈의 Vinho Verde의 레드 및 화이트 와인 데이터에서 일부 발췌 (민감한 정보 제외)
데이터 세트
아래 링크에서 다운로드 가능
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
1) 회귀 모델
- 와인 품질 예측
알고리즘
Linear Regression
변수 선정
PFI 과정은 학습된 모델을 기반으로 특성의 중요도를 평가
PFI는 모델이 실제로 예측하는 성능을 기준으로 특성의 중요도를 평가
PFI 설정은 다음과 같다
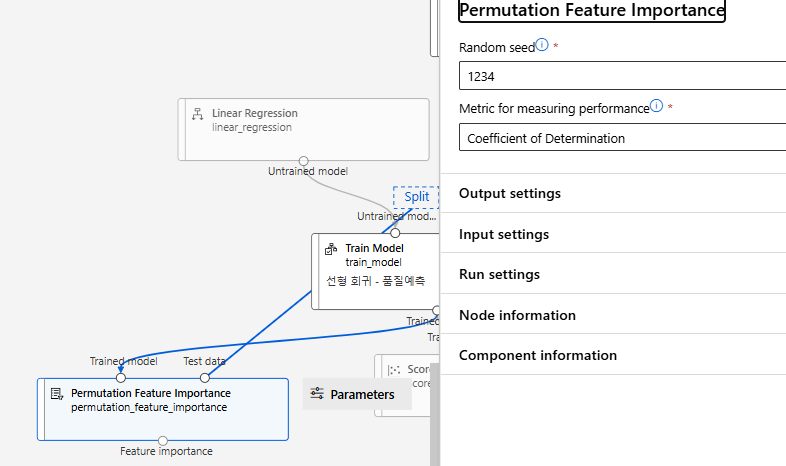
PFI 결과

상위 2개 제외하고 다시 진행

2) 분류 모델
- Red wine, White wine 구분
- 분류하려고 하는 type은 카테고리와 하여 Indicator Value로 변환하면 안됨
-> 에러

- 너무 완벽한 결과가 나와 PFI 로 변수 측정

PFI 결과

5개 항목 제외 하고 다시 진행

아까 보다 결과가 개선되었음을 알 수 있다
오늘의 간단한 후기
개인실습을 해보면서 원하는 결과가 얻기 정말 힘들 다는 것을 깨달았다. 종속 변수와의 종속성이 너무 커도 문제가 일어나기 때문이다. 어떤 변수를 선정해서 분석해야하는 지 파악하는 것이 정말 힘들다는 것을 알았다. 데이터에 대한 기본적인 이해는 물론이고 통계에 대한 지식도 있어야 한다는 것을 새삼알게 되었다
출처
[1] ScribblingAnything, "[머신러닝] Regression Tree란? 예제로 쉽게 이해하기," *ScribblingAnything Blog*, https://scribblinganything.tistory.com/711 (accessed Jan. 21, 2025).
[2] Analytics Vidhya, "How SVM (Support Vector Machine) is different from others," *Medium*, https://medium.com/analytics-vidhya/how-svm-support-vector-machine-is-different-from-others-18eb7ce196c1 (accessed Jan. 21, 2025).
[3] UCI Machine Learning Repository, "Statlog (German Credit Data)," https://archive.ics.uci.edu/dataset/144/statlog+german+credit+data (accessed Jan. 21, 2025).
[4] sp1rit, "회귀 (Regression)," *Velog*, https://velog.io/@sp1rit/%ED%9A%8C%EA%B7%80Regression (accessed Jan. 21, 2025).
[5] Jongguman, "회귀 분석이란?" *Naver Blog*, https://m.blog.naver.com/jongguman/220770217672 (accessed Jan. 21, 2025).
[6] Altruist Delhite04, "Loan Prediction Problem Dataset," *Kaggle*, https://www.kaggle.com/datasets/altruistdelhite04/loan-prediction-problem-dataset (accessed Jan. 21, 2025).
[7] Incodom, "SMOTE," https://incodom.kr/SMOTE (accessed Jan. 21, 2025).
[8] Day-to-Day, "SMOTE란 무엇인가?" *Tistory*, https://day-to-day.tistory.com/32?category=1044285 (accessed Jan. 21, 2025).
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(강명호 강사님)을 기반으로 제작되었습니다
깃허브 소스코드의 내용을 담고 있습니다
Microsoft에서 제공하는 Dataset을 포함하고 있습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다



