

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 마이크로소프트 ai 스쿨 6기
- 마이크로소프트 ai 스쿨
- micsrosoft ai
- MS
- msai
- microsoft ai school 6기
- 마이크로소프트
- 마이크로소프트 AI
- microsoft ai school
- 마이크로소프트 ai school 6기
- microsoft
- 마이크로소프트 ai 스클
- microsoft ai
- Today
- Total
연랩
[Microsoft AI School 6기] 1/23(26일차) 정리 - 회귀 코딩, 분류 코딩 본문
회귀 코딩
공공자전거 수요예측
- 목표 : 특정 시간의 공공자전거 대여량 예측(회귀)
- 목적 : 공공자전거의 적절한 배치와 관리
데이터 수집
아래의 링크에서 데이터 수집이 가능하다
Bike Sharing Demand | Kaggle
데이터 불러오기
데이터를 불러올 때 유의할점은 datetime 칼럼을 datetime으로 읽어오고 싶으면
parse_dates=['datetime']
옵션을 사용한다
-> 옵션 선정하지 않으면 string으로 읽어옴

-> 범주형 변수가 있는 지 살펴보아야 한다
ex) season, holiday, workingday, weather ...
예측하고자 하는 것 : count
casual, registered는 독립 변수로 쓸 수 없다
데이터 탐색(EDA)
datetime

연도, 월별 등 평균으로 비교 하였다
디폴트는 평균으로 되어 있다.
ex) sum으로 바꾸면 합산을 비교
- dayofweek는 0번이 월요일이다
시간대별 대여량은 다음과 같다

주말과 평일의 시간대별 대여량이 매우 다름을 알 수 있다
Season

- 봄, 여름, 가을, 겨울로 되어 있으나, 사실상 분기가 기준임을 알 수 있다
월별 평균 대여량은 다음과 같다

Holiday

공휴일의 수가 적기 때문에 sum으로 간주하면 잘못된 결과가 나올 수 있다
-> 평균으로 관찰하는 것이 낫다
working day

마찬가지로 평일이 더 많기 때문에 평균으로 계산하여야 한다
weather
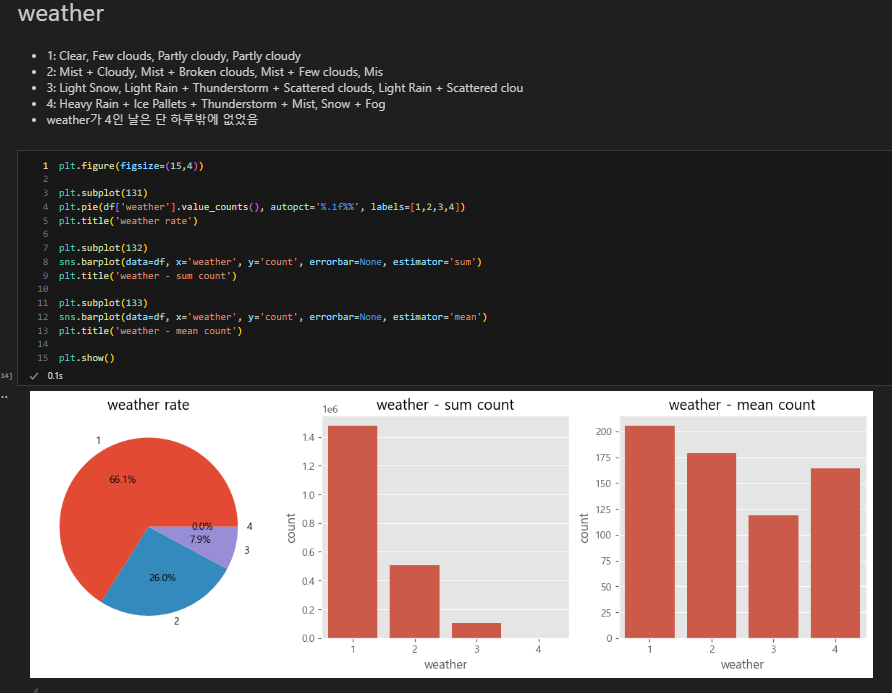
날씨가 안좋은 날(4번)은 딱 하루이기 때문에 분모가 작아져 평균 대여량 수가 많아졌음을 알 수 있다
temp
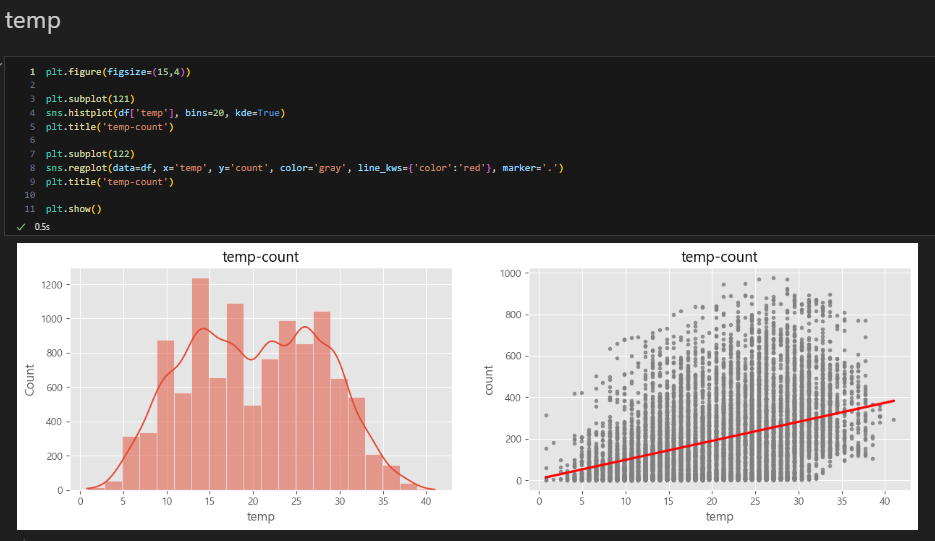
수치형 데이터
구간별로 히스토그램을 그리거나 산점도를 찍어봐야 함
temp가 올라갈수록 count가 올라감을 알 수 있다
-> 따뜻한 날일수록 대여를 많이 함
atemp
체감 온도

기온이 올라갈수록 대여량이 올라가는 경향이 있음
Humidity

상대습도가 떨어질 수록 대여량이 올라감
음의 상관관계가 있다
windspeed
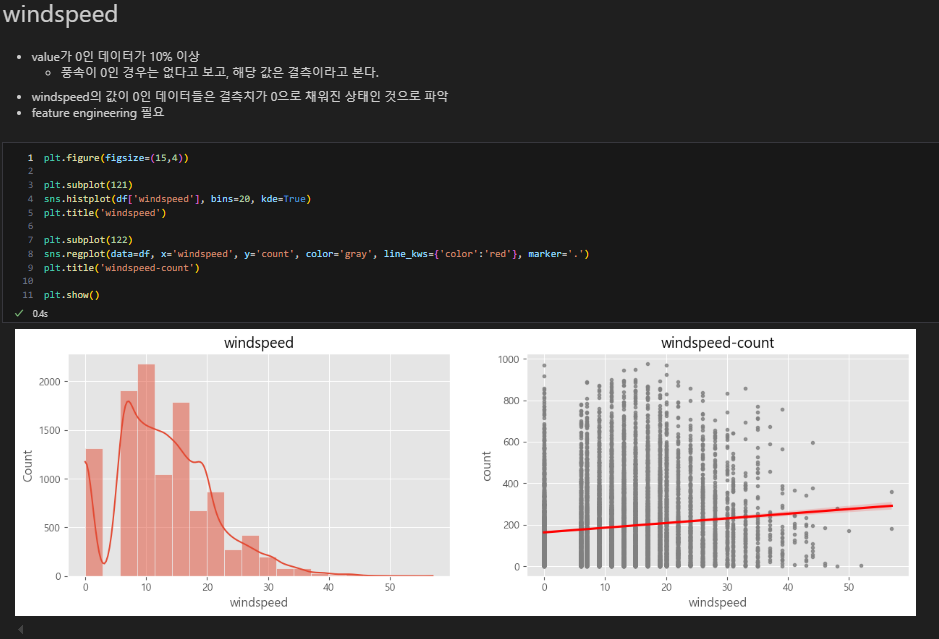
0이 많은 것을 보니 결측값이 많은 데이터일 수 있다는 생각을 할 수 있음
상관계수
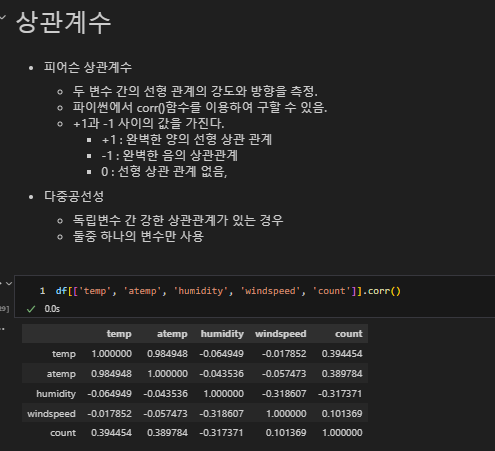
heatmap을 그려 보면 다음과 같다

그러나 음의 상관관계가 있기 때문에 절대값을 취해 주어야 한다
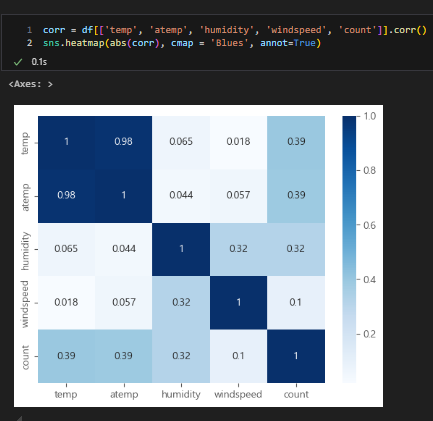
atemp와 temp가 상관관계가 매우 높음을 알 수 있다
다중공선성이 존재한다고 함
: 독립변수 간의 강한 상관관계가 존재
-> 다중공선성은 제거해주어야 함
PCA를 쓰는 방법이 있지만, 해당 실습에서는 두 변수 중 한 변수 삭제
Linear Regression
기본적으로 선형 회귀 공식을 만들어 예측하면 다음과 같이 나온다

모델 평가
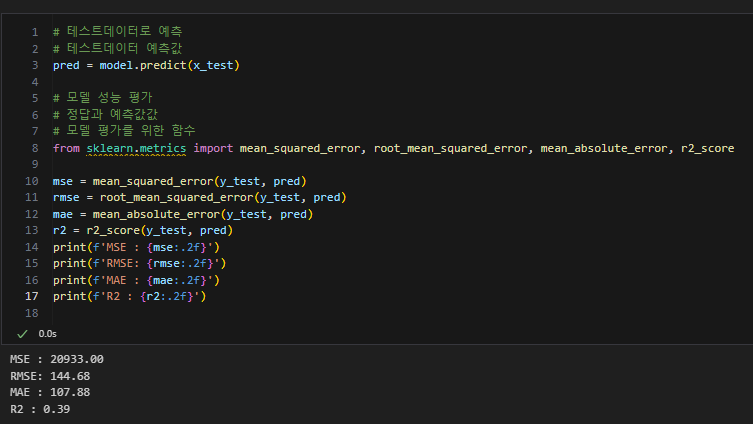
성능이 별로 좋지 않음을 알 수 있다.
따라서 이를 위한 개선이 필요하다
원핫 인코딩
ex) year의 경우 2011, 2012로 범위가 너무 크기 때문에 원핫인코딩을 해준다
pd.get_dummies( 데이터셋, columns = [])

변수가 매우 증가했음을 알 수 있다
- indivator value로 변경
다시 데이터 세트를 분류하고 모델을 생성, 훈련, 평가하면 다음과 같다

성능이 훨씬 개선되었음을 알 수 있다
이후, 데이터를 변경해 가면서 최선의 모델을 찾을 수 있다.
종속변수 로그 변환
종속 변수를 살펴보면, 한쪽으로 치우쳐 있음을 알 수 있다

위에서 x를 원핫인코딩으로 변환한 것처럼
종속변수 y도 로그 변환을 하여 전처리를 해준다
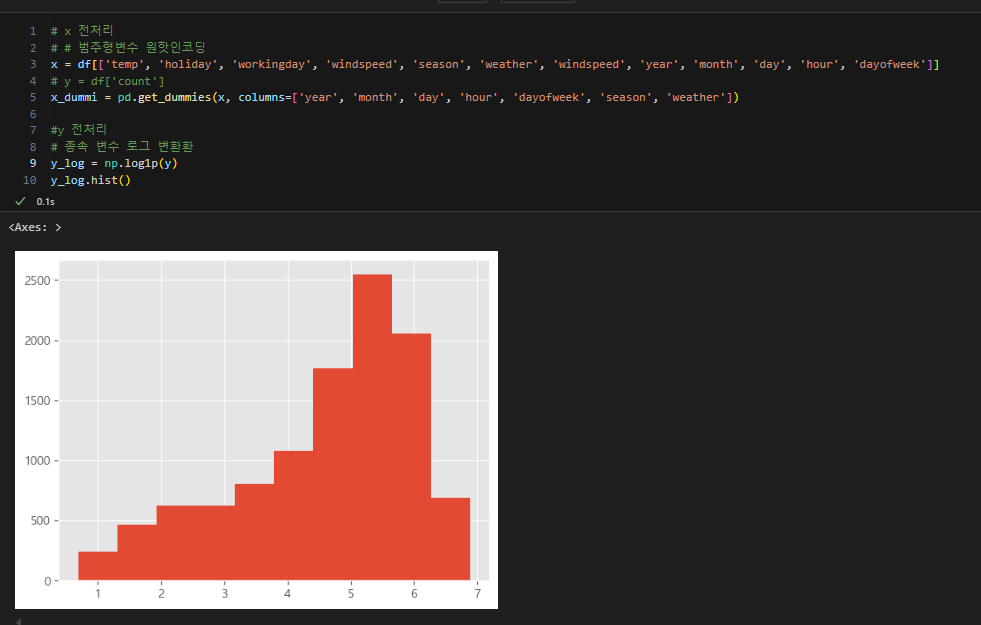
로그 역변환
실제 count를 알려면 -> 로그 역변환을 해주어야 함
np.expm1()

종속 변수에 로그를 취한 것이 성능이 더 좋은 것을 확인할 수 있다
모델의 평가 방법
홀드아웃 검증(Holdout method)
- 전체 데이터를 훈련용/테스트용으로 또는 훈련용/검증용/테스트용으로 분할
k-폴드 교차 검증(k-Fold Cross Validation)
학습 데이터를 k개의 동일한 크기의 부분집합으로 나누고, k-1개의 집단을 학습용으로, 나머지는 검증용으로 설정하여 학습 k번 반복 측정한 결과를 평균 낸 값을 검증 결과값으로 사용
kfold-cross validation
이미 다른 모델들은 학습이 되어 있기 때문에 새로운 모델 생성
cv는 교차 검증(Cross-Validation)을 수행할 때 사용할 데이터 분할 방식을 지정

교차 검증을 해보면 위와 같다
x를 원핫인코딩 했을 떄, y를 로그 변환했을 때 결과가 더 좋아짐을 알 수 있다
평균으로 계산해보면 다음과 같다

분류 코딩
Logistic Regression
- 종속 변수가 범주형일 때, 수행할 수 있는 회귀분석 기법의 한 종류
- 독립변수들의 선형 결합을 이용하여 개별 관측치가 속하는 집단을 확률로 예측
- 선형회귀의 출력값을 시그모이드 함수에 입력하여 0~1 사이의 확률로 변환

K-Nearest Neighbors, KNN 알고리즘
- 새로운 데이터 포인트의 클래스나 값을 결정할 때, 가장 가까운 K개의 이웃 데이터 포인트를 참조하는 방식
- 학습 과정 없이 훈련 데이터에서 가장 가까운 K개의 이웃을 찾아 그들의 정보를 기반으로 분류나 회귀 수행
장점
- 단순성 : 구현이 간단하고 이해하기 쉬움
- 훈련 과정이 빠름
단점
- 이상치에 민감 (피처 스케일링이 중요함)
- 피처의 중요도를 반영하지 않음
Decision Tree
데이터의 특성을 바탕으로 분기를 만들어 트리 구조로 의사결정 과정을 모델링하는 방법
- Root node에서 시작하여 조건에 따라 데이터를 분할하고, 이 과정을 반복하여 Leaf node에서 예측 결과를 도출
- 분류 및 회귀를 모두 지원
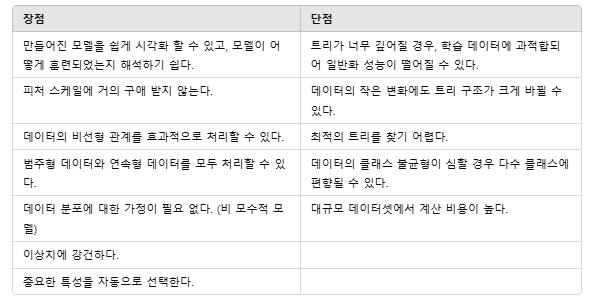
가지치기를 위한 하이퍼 파라미터
목적 : 트리의 복잡성 감소 → 과적합(Overfitting) 방지 → 일반화 성능 향상
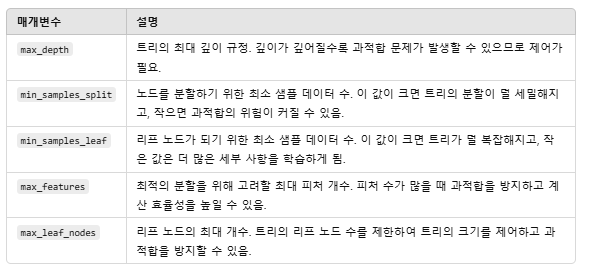
과도한 가지치기는 underfitting을 발생시킬 수 있으므로 적정한 수준의 가지치기 필요
앙상블(ensemble)
앙상블 개요

앙상블 학습의 유형

- 부스팅이 성능이 더 좋은 경향이 있음
Boosting 알고리즘의 주요 개념
- 순차적 학습 : 여러 약한 학습기(Weak learner)를 순차적으로 학습시킨다.
- 가중치 조절 : 모델이 학습하는 동안 잘못 예측한 데이터에 더 높은 가중치를 부여하여 이후 모델이 이를 더 정확하게 예 측할 수 있도록 유도한다.
- 최종 모델 : 여러 모델의 예측을 결합하여 최종 모델을 만든다. 이 때 각 학습기의 중요도에 따라 가중치가 부여된다

분류 모델의 성능 평가 지표
- 혼동 행렬(Confusion Matrix)
- 정확도(Accuracy)
- 정밀도(Precision)
- 재현률(또는 민감도) - Recall(or Sensitivity)
- F1 Score
- ROC 곡선과 AUS
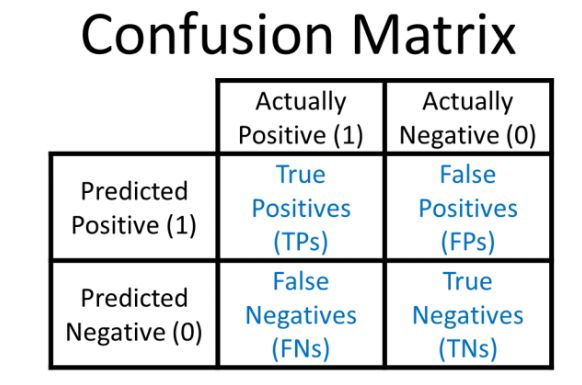
재현률: 실제 Positive 한 것 중 Posivite 예측 비율
TP/TP+FN
ex) 암진단, 범죄자 식별
실제 범죄자를 범죄자로 식별한 비율
-> 정밀도가 낮으면 실제 범죄자를 범죄자가 아니라고 식별
정밀도: Positive로 예측, 중 Positive 비율
TP/TP+FP
ex) 스팸 필터링, 광고타겟팅
- 스팸 메일함에 넣었는데 진짜 스팸일 확률
F1 score: 값이 클수록 모델의 성능이 좋음을 의미
ROC curve

실습
- 붓꽃 품종 예측
목적: 붓꽃의 특성(꽃잎의 길이와 너비, 꽃받침의 길이와 너비)를 기반으로 붓꽃의 품종을 예측한다
데이터 준비하기
sklearn에서 제공하는 샘플 데이터셋을 활용
라이브러리 import 및 데이터 불러오기

iris data = dictionary 형
데이터 이해

각 분류에 비슷한 분포의 데이터가 들어 있는 지 확인

pairplot을 그려보면 위와 같다
hue를 이용하여 색 구별 가능 - 종을 기준으로 구별
변수간의 관계를 시각화하여 보면 학습의 품질을 짐작할 수 있다
데이터 전처리
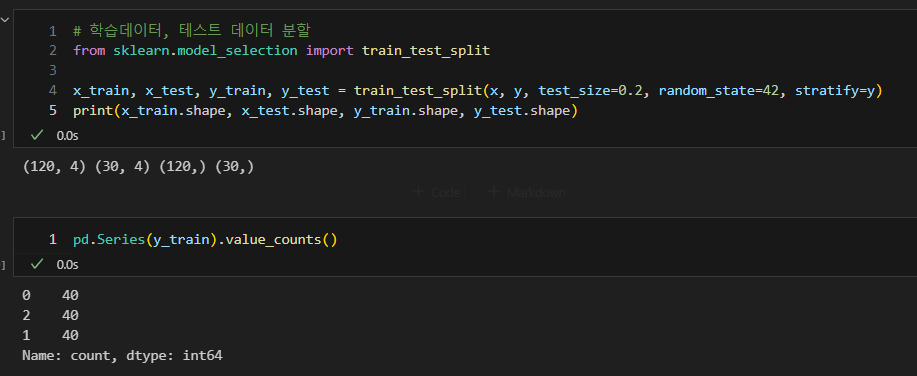
학습데이터, 테스트 데이터 분할

아래를 보면 랜덤으로 데이터 셋이 분할되어 클래스가 균등하지 않음을 알 수 있다
이를 균등하게 하기 위해서는 stratify 옵션을 사용한다
- y를 기준으로 균등하게 분할
모델 생성 및 훈련 -> 테스트 데이터로 예측
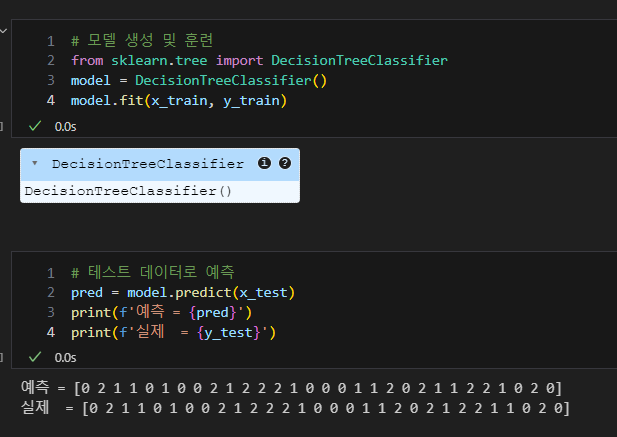
DecisionTreeClassifier에도 랜덤 시드를 설정 가능
모델 평가
accuracy_score 활용
- classification report 사용하면 한번에 볼 수 있음

트리 시각화
트리의 구조를 파악하기 위해 트리를 시각화하면 다음과 같다
plot_tree(model)


gini: 불순도
gini가 낮은 방향으로 분할
특성의 중요도
특성의 중요도를 살펴보면 다음과 같다

어떻게 분할하느냐에 따라 변수가 달라지는 경우 k-fold 사용 가능(교차 검증)
트리의 깊이
교차 검증
StratifiedKFold:
교차 검증(Cross Validation)의 한 방법으로, 데이터셋을 나눌 때 클래스의 분포를 동일하게 유지하도록 설계
-> 분류에서는 KFold 말고 StratifiedKFold 사용
split 시 xtrain, ytrain을 둘 다 주어야 함

학습용 데이터의 일부를 검증용으로 사용
kf.split을 통해 일부를 val에 해당
train으로 학습 -> val 대입 -> 정확도 확인
cv_scores.append()는 교차 검증(Cross Validation) 과정에서 각 폴드(fold)마다 계산된 모델의 성능 평가 점수를 리스트에 추가
val과 test의 차이
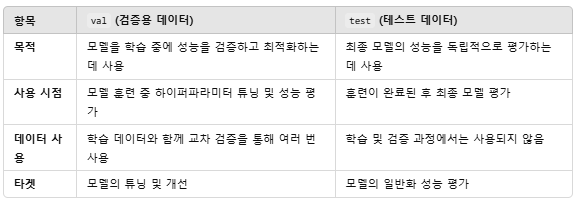
- test 데이터는 최종 성능 평가용, 모델이 학습과 검증 과정에서 전혀 접하지 않은 데이터로, 최종적으로 모델의 실제 예측 성능을 평가
- val 데이터는 모델 학습 중 하이퍼파라미터 튜닝이나 성능 조정을 위한 데이터입니다. 이 데이터는 모델이 학습하는 과정에서 사용되므로, 이 데이터에 대한 성능은 최종적인 평가 지표로는 적합하지 않습니다.
테스트는 아예 새로운 데이터로 해야함
val data는 훈련에 참여
-> 테스트 데이터 따로 분리
하이퍼 파라미터 튜닝
지정한 하이퍼파라미터를 순차적으로 변경하면서 교차검증을 수행하여 최적의 파라미터 조합을 찾는 방법
GridSeachCV
GridSeachCV 객체 생성(모델, 하이퍼파라미터그리드, 교차검증횟수) → GridSearchCV 객체에 학습용 데이터 전달하여 Grid Search Cross Validation 수행

display()로 데이터 프레임 프린트

train+val
- Grid search CV
-> 교차 검증으로 최적 파라미터 찾음
-> 해당 모델로
test 데이터로 test

다른 모델과 비교
다른 모델과 비교하여 보면 다음과 같다
RandomForestClassifier
모델 및 교차 검증, 파라미터 학습
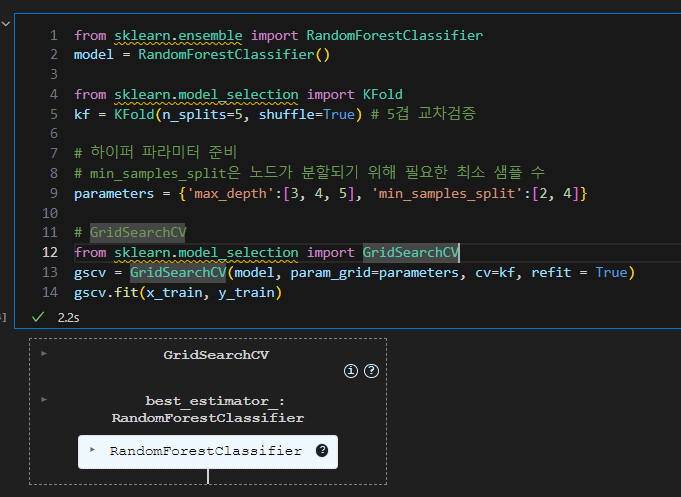
최적 파라미터 확인

파라미터 반영 최종 정확도 확인

오늘의 후기
시각적으로 결과를 관찰하고 코드로 내부 구조를 보니 이해가 쉬웠다. 사실 머신 러닝 부분은 수학적 지식이 바탕이 되어있지 않으면 쉽지 않겠다는 생각이 들었다. 교수님 강의자료가 좋아서 이해하기가 용이했다. 또한, 질문을 하면 답변해 주시는 분들이 많아 너무 감사했다
출처
[1] Kaggle, "Bike Sharing Demand Data," https://www.kaggle.com/competitions/bike-sharing-demand/data (accessed Jan. 23, 2025).
[2] Towards Data Science, "Logistic Regression Explained in 7 Minutes," *Towards Data Science*, https://towardsdatascience.com/logistic-regression-explained-in-7-minutes-f648bf44d53e (accessed Jan. 23, 2025).
[3] Glass Box Medicine, "Measuring Performance: The Confusion Matrix," *Glass Box Medicine*, https://glassboxmedicine.com/2019/02/17/measuring-performance-the-confusion-matrix/ (accessed Jan. 23, 2025).
[4] I. Yurek, "ROC Curve and AUC: Evaluating Model Performance," *Medium*, https://medium.com/@ilyurek/roc-curve-and-auc-evaluating-model-performance-c2178008b02 (accessed Jan. 23, 2025).
-If any problem for references, or any questions please contact me by comments.
-This content is only for recording my studies and personal profiles
일부 출처는 사진 내에 표기되어 있습니다
본문의 내용은 학습과 개인 profile 이외의 다른 목적이 없습니다
출처 관련 문제 있을 시 말씀 부탁드립니다
상업적인 용도로 사용하는 것을 금합니다
본문의 내용을 Elixirr 강의자료 내용(김자영)을 기반으로 제작되었습니다
깃허브 소스코드의 내용을 담고 있습니다
본문의 내용은 MS AI School 6기의 강의 자료 및 수업 내용을 담고 있습니다



